Publications
Selected publications in reversed chronological order. List of all publications @Google Scholar
2026
-
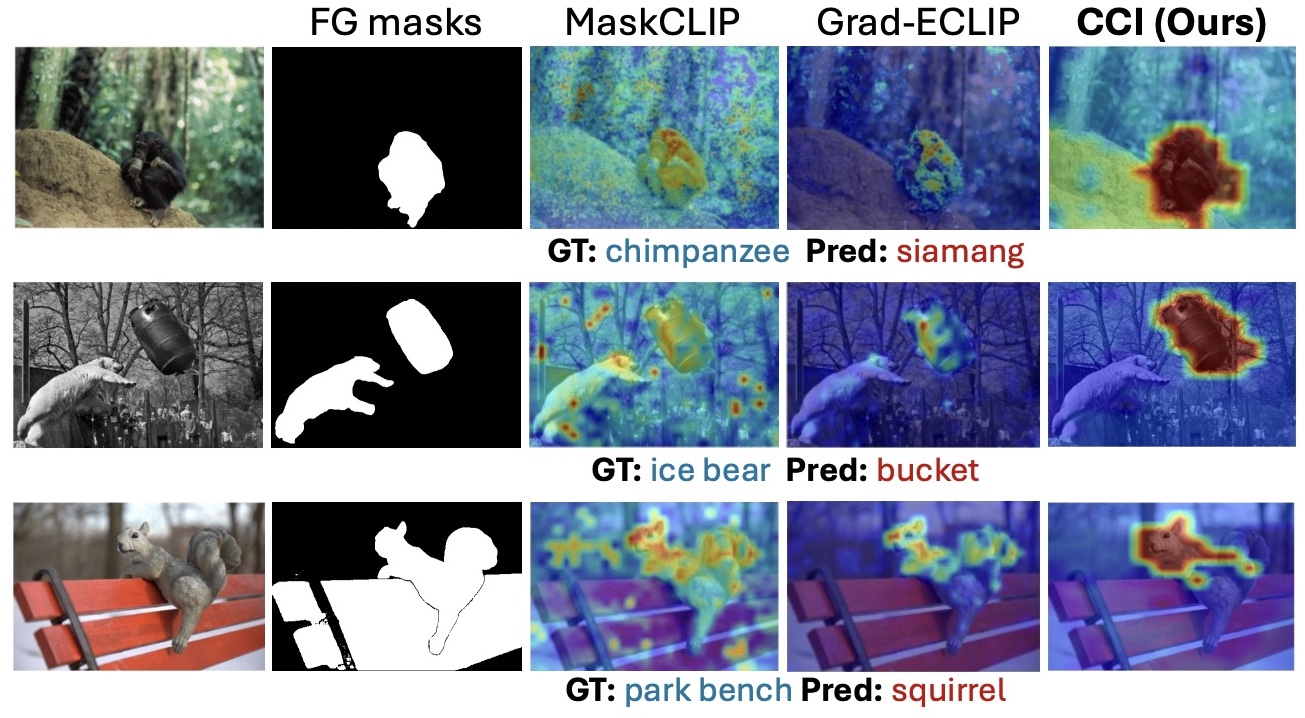 Concept Regions Matter: Benchmarking CLIP with a New Cluster-Importance ApproachAishwarya Agarwal, Srikrishna Karanam, and Vineet GandhiIn Conference on Computer Vision and Pattern Recognition (CVPR), 2026
Concept Regions Matter: Benchmarking CLIP with a New Cluster-Importance ApproachAishwarya Agarwal, Srikrishna Karanam, and Vineet GandhiIn Conference on Computer Vision and Pattern Recognition (CVPR), 2026Contrastive vision-language models (VLMs) such as CLIP achieve strong zero-shot recognition yet remain vulnerable to spurious correlations, particularly background over-reliance. We introduce Cluster-based Concept Importance (CCI), a novel interpretability method that uses CLIP’s own patch embeddings to group spatial patches into semantically coherent clusters, mask them, and evaluate relative changes in model predictions. CCI sets a new state of the art on faithfulness benchmarks, surpassing prior methods by large margins; for example, it yields more than a twofold improvement on the deletion-AUC metric for MS COCO retrieval. We further propose that CCI, when combined with GroundedSAM, automatically categorizes predictions as foreground- or background-driven, providing a crucial diagnostic ability. Existing benchmarks such as CounterAnimals, however, rely solely on accuracy and implicitly attribute all performance degradation to background correlations. Our analysis shows this assumption to be incomplete, since many errors arise from viewpoint variation, scale shifts, and fine-grained object confusions. To disentangle these effects, we introduce COVAR, a benchmark that systematically varies object foregrounds and backgrounds. Leveraging CCI with COVAR, we present a comprehensive evaluation of eighteen CLIP variants, offering methodological advances and empirical evidence that chart a path toward more robust VLMs.
@inproceedings{CVPR_CCI_2026, author = {Agarwal, Aishwarya and Karanam, Srikrishna and Gandhi, Vineet}, title = {{Concept Regions Matter: Benchmarking CLIP with a New Cluster-Importance Approach}}, year = {2026}, booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)}, month = jun, } -
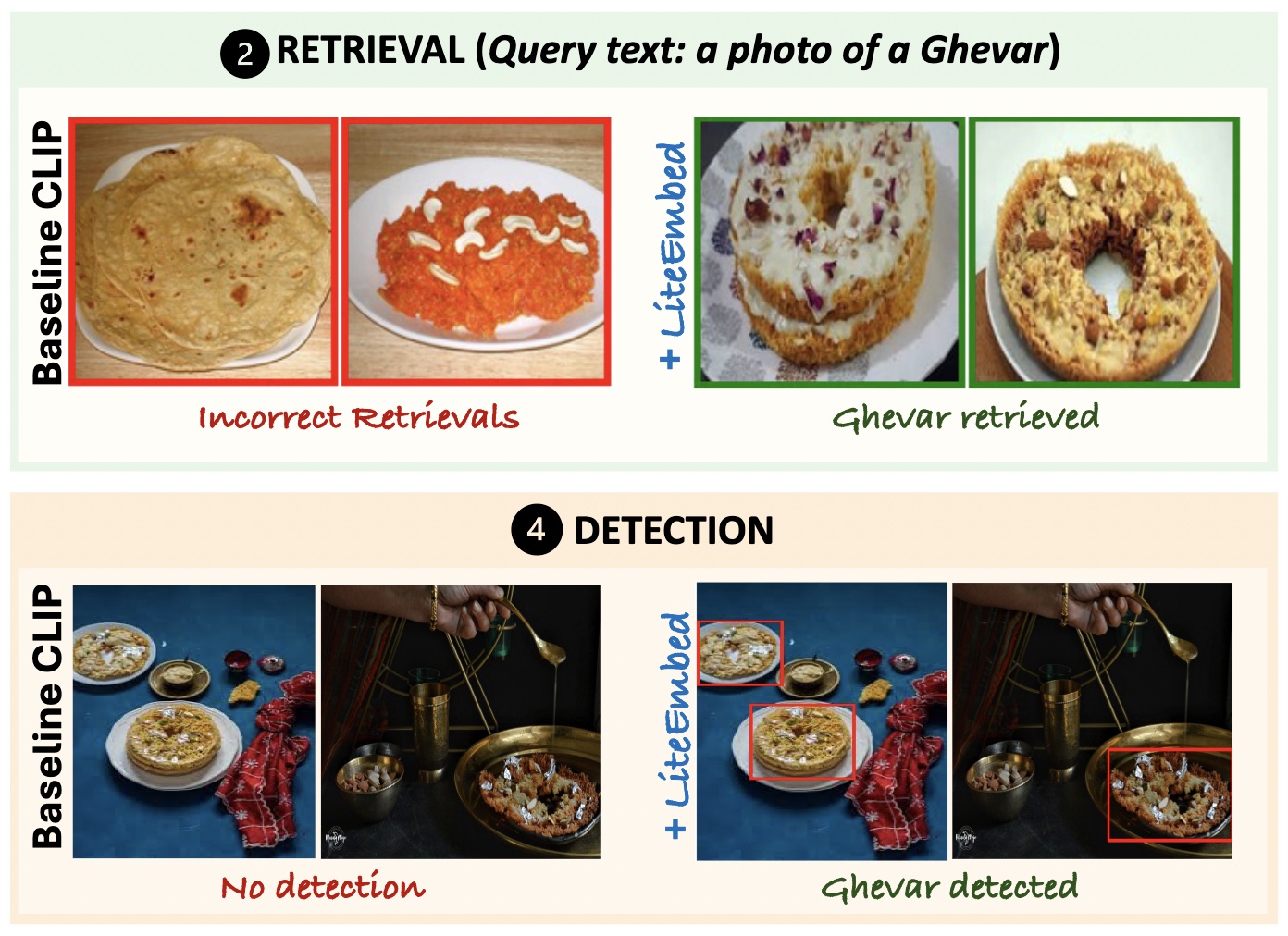 LiteEmbed: Adapting CLIP to Rare ClassesAishwarya Agarwal, Srikrishna Karanam, and Vineet GandhiIn Conference on Computer Vision and Pattern Recognition (CVPR), Findings, 2026
LiteEmbed: Adapting CLIP to Rare ClassesAishwarya Agarwal, Srikrishna Karanam, and Vineet GandhiIn Conference on Computer Vision and Pattern Recognition (CVPR), Findings, 2026Large-scale vision–language models such as CLIP achieve strong zero-shot recognition but struggle with classes rarely seen in pretraining, including newly emerging entities and culturally specific classes. We introduce LiteEmbed, a lightweight framework for few-shot personalization of CLIP that enables new classes to be added without retraining its encoders. LiteEmbed performs subspace-guided optimization of text embeddings within CLIP’s vocabulary, leveraging a PCA-based decomposition that disentangles coarse semantic directions from fine-grained variations. Two complementary objectives, coarse alignment and fine separation, jointly preserve global semantic consistency while enhancing discriminability among visually similar classes. Once optimized, the embeddings are plug-and-play, seamlessly substituting CLIP’s original text features across classification, retrieval, segmentation, and detection. Extensive experiments demonstrate substantial gains over prior methods, establishing LiteEmbed as an effective approach for adapting CLIP to underrepresented, rare or unseen classes
@inproceedings{CVPR_liteembed_2026, author = {Agarwal, Aishwarya and Karanam, Srikrishna and Gandhi, Vineet}, title = {{LiteEmbed: Adapting CLIP to Rare Classes}}, year = {2026}, booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR), Findings}, month = jun, } -
 CLARIS: Clear and Intelligible Speech from Whispered and Dysarthric VoicesNeil Shah, Yash Sonkar, Shirish Karande, and Vineet GandhiIn Conference on Human Factors in Computing Systems (CHI), 2026
CLARIS: Clear and Intelligible Speech from Whispered and Dysarthric VoicesNeil Shah, Yash Sonkar, Shirish Karande, and Vineet GandhiIn Conference on Human Factors in Computing Systems (CHI), 2026Whispered and dysarthric speech hinder effective communication and undermine the reliability of voice-enabled systems. We present CLARIS, a compact speech-to-speech restoration system that turns such atypical input into clear, expressive speech. CLARIS requires no disorder-specific architectural tuning, generalizes across lan- guages, and adapts quickly to new accents and speakers, enabling practical personalization. On whispered English, Hindi, and clinically challenging dysarthric speech, CLARIS delivers state-of-the-art intelligibility and naturalness, with listener studies confirming gains in quality, intelligibility, naturalness, and prosody. The system runs in real time, converting one second of input in about 30ms and enables inclusive, private, and personalized voice interaction. Audio samples are available at https://claris-w2s.github.io/CLARIS/
@inproceedings{Shah_CHI_2026, author = {Shah, Neil and Sonkar, Yash and Karande, Shirish and Gandhi, Vineet}, title = {{CLARIS: Clear and Intelligible Speech from Whispered and Dysarthric Voices}}, year = {2026}, booktitle = {Conference on Human Factors in Computing Systems (CHI)}, month = apr, }
2025
-
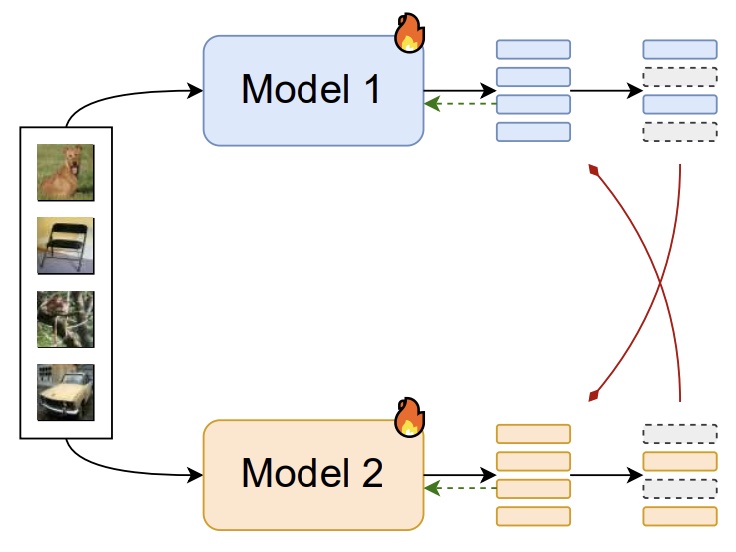 Simplifying Knowledge Transfer in Pretrained ModelsSiddharth Jain, Shyamgopal Karthik, and Vineet GandhiIn Transactions on Machine Learning Research (TMLR), 2025
Simplifying Knowledge Transfer in Pretrained ModelsSiddharth Jain, Shyamgopal Karthik, and Vineet GandhiIn Transactions on Machine Learning Research (TMLR), 2025Pretrained models are ubiquitous in the current deep learning landscape, offering strong results on a broad range of tasks. Recent works have shown that models differing in various design choices exhibit categorically diverse generalization behavior, resulting in one model grasping distinct data-specific insights unavailable to the other. In this paper, we propose to leverage large publicly available model repositories as an auxiliary source of model improvements. We introduce a data partitioning strategy where pretrained models autonomously adopt either the role of a student, seeking knowledge, or that of a teacher, imparting knowledge. Experiments across various tasks demonstrate the effectiveness of our proposed approach. In image classification, we improved the performance of ViT-B by approximately 1.4% through bidirectional knowledge transfer with ViT-T. For semantic segmentation, our method boosted all evaluation metrics by enabling knowledge transfer both within and across backbone architectures. In video saliency prediction, our approach achieved a new state-of-the-art. We further extend our approach to knowledge transfer between multiple models, leading to considerable performance improvements for all model participants.
@inproceedings{Jain_TMLR_2025, author = {Jain, Siddharth and Karthik, Shyamgopal and Gandhi, Vineet}, title = {{Simplifying Knowledge Transfer in Pretrained Models}}, year = {2025}, booktitle = {Transactions on Machine Learning Research (TMLR)}, month = sep, } -
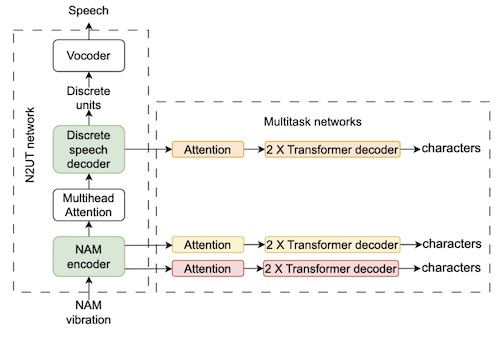 NAM-to-Speech Conversion with Multitask-Enhanced Autoregressive ModelsNeil Shah, Shirish Karande, and Vineet GandhiIn Interspeech, 2025
NAM-to-Speech Conversion with Multitask-Enhanced Autoregressive ModelsNeil Shah, Shirish Karande, and Vineet GandhiIn Interspeech, 2025We propose an alignment-free, end-to-end Non-Audible Murmur (NAM)-to-Speech conversion model. Existing methods rely on large NAM-text pairs per speaker to generate high-quality alignments for training non-autoregressive models. However, alignment quality deteriorates when trained on multi-speaker data, limiting their ability to generalize and effectively utilize the available training data. To address this, we introduce a streamlined autoregressive approach that eliminates the need for explicit alignment learning. By leveraging multi-speaker samples, synthetic training pairs, and multitask character recognition training, our method reduces the word error rate (WER) by 59.19% compared to the state-of-the-art (SOTA) on two public datasets. We demonstrate the model’s zero-shot capability and validate the effectiveness of multitask training through ablation studies.
@inproceedings{Shah_Interspeech_2025, author = {Shah, Neil and Karande, Shirish and Gandhi, Vineet}, title = {{NAM-to-Speech Conversion with Multitask-Enhanced Autoregressive Models}}, year = {2025}, booktitle = {Interspeech}, month = aug, } -
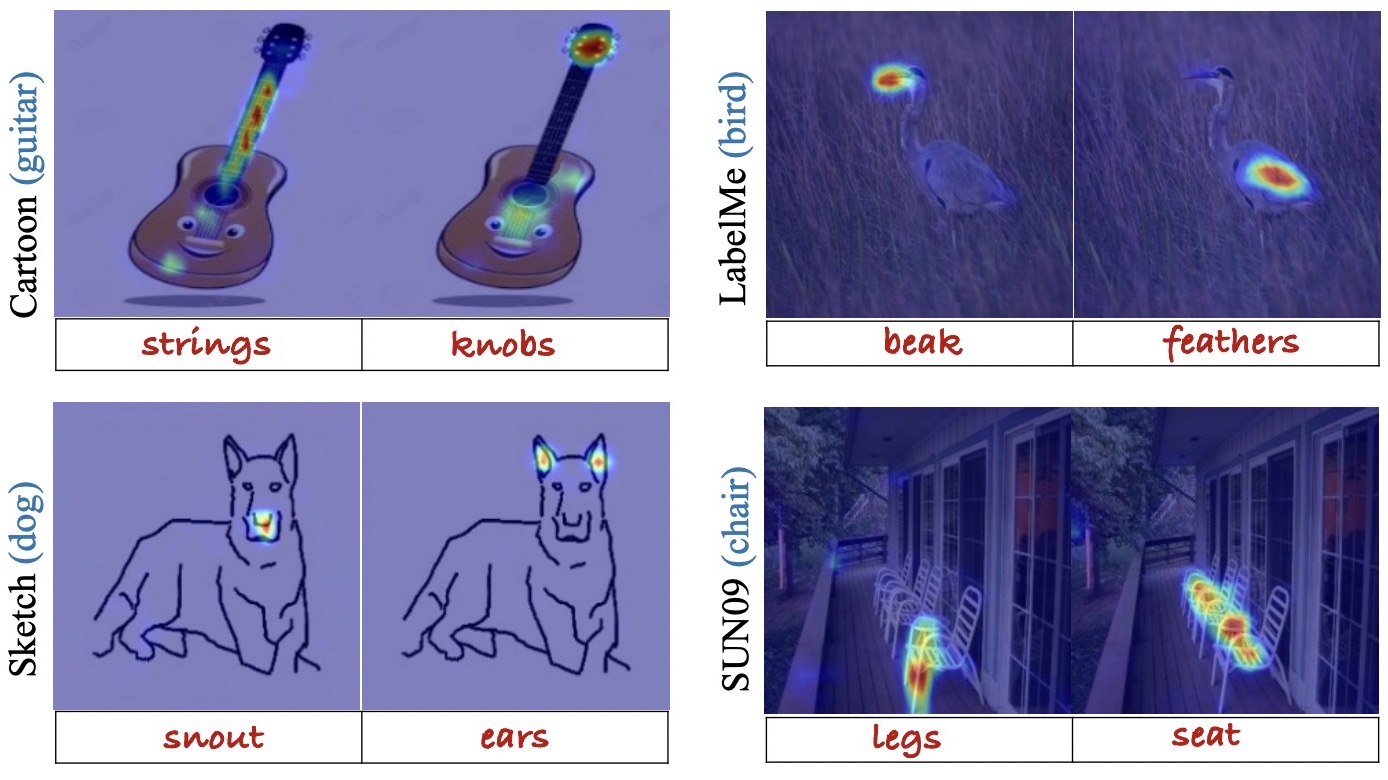 TIDE: Training Locally Interpretable Domain Generalization Models Enables Test-time CorrectionAishwarya Agarwal, Srikrishna Karanam, and Vineet GandhiIn Conference on Computer Vision and Pattern Recognition (CVPR), 2025Note: presented as Highlight
TIDE: Training Locally Interpretable Domain Generalization Models Enables Test-time CorrectionAishwarya Agarwal, Srikrishna Karanam, and Vineet GandhiIn Conference on Computer Vision and Pattern Recognition (CVPR), 2025Note: presented as HighlightWe consider the problem of single-source domain generalization. Existing methods typically rely on extensive augmentations to synthetically cover diverse domains during training. However, they struggle with semantic shifts (e.g., background and viewpoint changes), as they often learn global features instead of local concepts that tend to be domain invariant. To address this gap, we propose an approach that compels models to leverage such local concepts during prediction. Given no suitable dataset with per-class concepts and localization maps exists, we first develop a novel pipeline to generate annotations by exploiting the rich features of diffusion and large-language models. Our next innovation is TIDE, a novel training scheme with a concept saliency alignment loss that ensures model focus on the right per-concept regions and a local concept contrastive loss that promotes learning domain-invariant concept representations. This not only gives a robust model but also can be visually interpreted using the predicted concept saliency maps. Given these maps at test time, our final contribution is a new correction algorithm that uses the corresponding local concept representations to iteratively refine the prediction until it aligns with prototypical concept representations that we store at the end of model training. We evaluate our approach extensively on four standard DG benchmark datasets and substantially outperform the current state-ofthe-art (12% improvement on average) while also demonstrating that our predictions can be visually interpreted
@inproceedings{TIDE2025, info = {Also at CVPR Workshop on DG-EBE}, author = {Agarwal, Aishwarya and Karanam, Srikrishna and Gandhi, Vineet}, title = {TIDE: Training Locally Interpretable Domain Generalization Models Enables Test-time Correction}, year = {2025}, booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)}, month = jun, note = {Note: presented as Highlight} } -
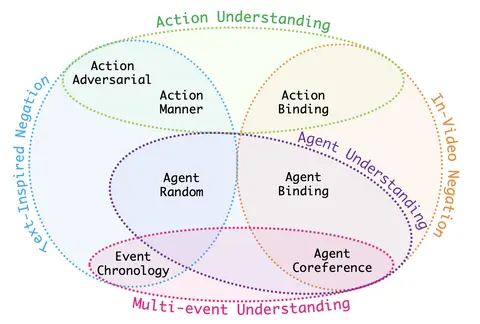 VELOCITI: Benchmarking Video-Language Compositional Reasoning with Strict EntailmentDarshana Saravanan, Varun Gupta, Darshan Singh, Zeeshan Khan, Vineet Gandhi, and Makarand TapaswiIn Conference on Computer Vision and Pattern Recognition (CVPR), 2025
VELOCITI: Benchmarking Video-Language Compositional Reasoning with Strict EntailmentDarshana Saravanan, Varun Gupta, Darshan Singh, Zeeshan Khan, Vineet Gandhi, and Makarand TapaswiIn Conference on Computer Vision and Pattern Recognition (CVPR), 2025A fundamental aspect of compositional reasoning in a video is associating people and their actions across time. Recent years have seen great progress in general-purpose vision or video models and a move towards long-video understanding. While exciting, we take a step back and ask: are current models good at compositional reasoning on short videos? To this end, we introduce VELOCITI, a benchmark to study Video-LLMs by disentangling and assessing the comprehension of agents, actions, and their associations across multiple events. We adopt the Video-Language Entailment setup and propose StrictVLE that requires correct classification (rather than ranking) of the positive and negative caption. We evaluate several models and observe that even the best, LLaVA-OneVision (44.5%) and Gemini-1.5-Pro (49.3%), are far from human accuracy at 93.0%. Results show that action understanding lags behind agents, and negative captions created using entities appearing in the video perform worse than those obtained from pure text manipulation. We also present challenges with ClassicVLE and multiple-choice (MC) evaluation, strengthening our preference for StrictVLE. Finally, we validate that our benchmark requires visual inputs of multiple frames making it ideal to study video-language compositional reasoning.
@inproceedings{DDV2025_Velociti, info = {Also at CVPR Workshops: VidLLMs, EVAL-FoMo, WiCV, MMFM}, author = {Saravanan, Darshana and Gupta, Varun and Singh, Darshan and Khan, Zeeshan and Gandhi, Vineet and Tapaswi, Makarand}, title = {VELOCITI: Benchmarking Video-Language Compositional Reasoning with Strict Entailment}, year = {2025}, booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)}, month = jun, } -
 Investigating Mechanisms for In-Context Vision Language BindingDarshana Saravanan, Makarand Tapaswi, and Vineet GandhiIn CVPR Workshop on Mechanistic Interpretability in Vision (MIV), 2025
Investigating Mechanisms for In-Context Vision Language BindingDarshana Saravanan, Makarand Tapaswi, and Vineet GandhiIn CVPR Workshop on Mechanistic Interpretability in Vision (MIV), 2025To understand a prompt, Vision-Language models (VLMs) must perceive the image, comprehend the text, and build associations within and across both modalities. For instance, given an ’image of a red toy car’, the model should associate this image to phrases like ’car’, ’red toy’, ’red object’, etc. Feng and Steinhardt propose the Binding ID mechanism in LLMs, suggesting that the entity and its corresponding attribute tokens share a Binding ID vector in the model activations. We investigate this for image-text binding in VLMs using a synthetic dataset and task that requires models to associate 3D objects in an image with their descriptions in the text. Our experiments demonstrate that VLMs assign a distinct Binding ID to an object’s image tokens and its textual references, enabling in-context association.
@inproceedings{Saravanan2025_BindingID, author = {Saravanan, Darshana and Tapaswi, Makarand and Gandhi, Vineet}, title = {{Investigating Mechanisms for In-Context Vision Language Binding}}, year = {2025}, booktitle = {CVPR Workshop on Mechanistic Interpretability in Vision (MIV)}, month = jun, } - Best paper
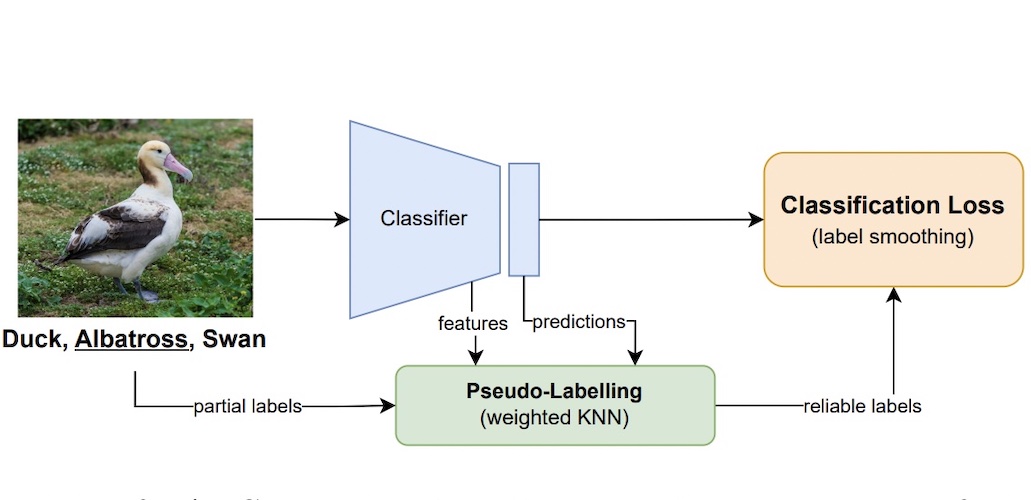 Pseudo-labelling meets Label Smoothing for Noisy Partial Label LearningDarshana Saravanan, Naresh Manwani, and Vineet GandhiIn CVPR Workshop on Workshop on Fine-Grained Visual Categorization (FGVC), 2025
Pseudo-labelling meets Label Smoothing for Noisy Partial Label LearningDarshana Saravanan, Naresh Manwani, and Vineet GandhiIn CVPR Workshop on Workshop on Fine-Grained Visual Categorization (FGVC), 2025We motivate weakly supervised learning as an effective learning paradigm for problems where curating perfectly annotated datasets is expensive and may require domain expertise such as fine-grained classification. We focus on Partial Label Learning (PLL), a weakly-supervised learning paradigm where each training instance is paired with a set of candidate labels (partial label), one of which is the true label. Noisy PLL (NPLL) relaxes this constraint by allowing some partial labels to not contain the true label, enhancing the practicality of the problem. Our work centres on NPLL and presents a framework that initially assigns pseudo-labels to images by exploiting the noisy partial labels through a weighted nearest neighbour algorithm. These pseudo-label and image pairs are then used to train a deep neural network classifier with label smoothing. The classifier’s features and predictions are subsequently employed to refine and enhance the accuracy of pseudo-labels. We perform thorough experiments on seven datasets and compare against nine NPLL and PLL methods. We achieve state-of-the-art results in all studied settings from the prior literature, obtaining substantial gains in the simulated fine-grained benchmarks. Further, we show the promising generalisation capability of our framework in realistic, fine-grained, crowd-sourced datasets.
@inproceedings{Saravanan2025_FGVC, author = {Saravanan, Darshana and Manwani, Naresh and Gandhi, Vineet}, title = {{Pseudo-labelling meets Label Smoothing for Noisy Partial Label Learning}}, year = {2025}, booktitle = {CVPR Workshop on Workshop on Fine-Grained Visual Categorization (FGVC)}, month = jun, info = {Best paper award}, } -
 IdentifyMe: A Challenging Mention Resolution Benchmark for LLMsKawshik Manikantan, Makarand Tapaswi, Vineet Gandhi, and Shubham ToshniwalIn Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics (NAACL), 2025Note: Short paper
IdentifyMe: A Challenging Mention Resolution Benchmark for LLMsKawshik Manikantan, Makarand Tapaswi, Vineet Gandhi, and Shubham ToshniwalIn Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics (NAACL), 2025Note: Short paperRecent evaluations of LLMs on coreference resolution have revealed that traditional output formats and evaluation metrics do not fully capture the models’ referential understanding. To address this, we introduce IdentifyMe, a new benchmark for mention resolution presented in a multiple-choice question (MCQ) format, commonly used for evaluating LLMs. IdentifyMe features long narratives and employs heuristics to exclude easily identifiable mentions, creating a more challenging task. The benchmark also consists of a curated mixture of different mention types and corresponding entities, allowing for a fine-grained analysis of model performance. We evaluate both closed- and open source LLMs on IdentifyMe and observe a significant performance gap (20-30%) between the state-of-the-art sub-10B open models vs. closed ones. We observe that pronominal mentions, which have limited surface information, are typically much harder for models to resolve than nominal mentions. Additionally, we find that LLMs often confuse entities when their mentions overlap in nested structures. The highest-scoring model, GPT-4o, achieves 81.9% accuracy, highlighting the strong referential capabilities of state-of-the-art LLMs while also indicating room for further improvement.
@inproceedings{Manikantan2025_IdentifyMe, note = {Note: Short paper}, author = {Manikantan, Kawshik and Tapaswi, Makarand and Gandhi, Vineet and Toshniwal, Shubham}, title = {{IdentifyMe: A Challenging Mention Resolution Benchmark for LLMs}}, year = {2025}, booktitle = {Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics (NAACL)}, month = may, } -
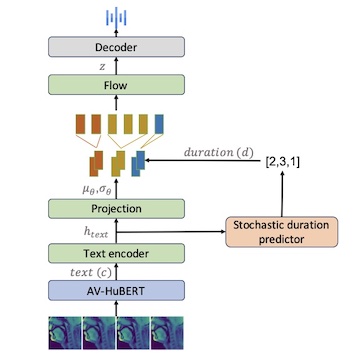 MRI2Speech:Speech Synthesis from Articulatory Movements Recorded by Real-time MRINeil Shah, Ayan Kashyap, Shirish Karande, and Vineet GandhiIn International Conference on Acoustics, Speech, and Signal Processing (ICASSP), 2025
MRI2Speech:Speech Synthesis from Articulatory Movements Recorded by Real-time MRINeil Shah, Ayan Kashyap, Shirish Karande, and Vineet GandhiIn International Conference on Acoustics, Speech, and Signal Processing (ICASSP), 2025Previous real-time MRI (rtMRI)-based speech synthesis models depend heavily on noisy ground-truth speech. Applying loss directly over ground truth mel-spectrograms entangles speech content with MRI noise, resulting in poor intelligibility. We introduce a novel approach that adapts the multi-modal self-supervised AV-HuBERT model for text prediction from rtMRI and incorporates a new flow-based duration predictor for speaker-specific alignment. The predicted text and durations are then used by a speech decoder to synthesize aligned speech in any novel voice. We conduct thorough experiments on two datasets and demonstrate our method’s generalization ability to unseen speakers. Our method achieves a 15.18% Word Error Rate (WER) on the USC-TIMIT MRI corpus, marking a huge improvement over the current state-of-the-art.
@inproceedings{Shah_ICASSP_MRI_2025, author = {Shah, Neil and Kashyap, Ayan and Karande, Shirish and Gandhi, Vineet}, title = {{MRI2Speech:Speech Synthesis from Articulatory Movements Recorded by Real-time MRI}}, year = {2025}, booktitle = {International Conference on Acoustics, Speech, and Signal Processing (ICASSP)}, month = apr, } -
 Advancing NAM-to-Speech Conversion with Novel Methods and the MultiNAM DatasetNeil Shah, Shirish Karande, and Vineet GandhiIn International Conference on Acoustics, Speech, and Signal Processing (ICASSP), 2025
Advancing NAM-to-Speech Conversion with Novel Methods and the MultiNAM DatasetNeil Shah, Shirish Karande, and Vineet GandhiIn International Conference on Acoustics, Speech, and Signal Processing (ICASSP), 2025Current Non-Audible Murmur (NAM)-to-speech techniques rely on voice cloning to simulate ground-truth speech from paired whispers. However, the simulated speech often lacks intelligibility and fails to generalize well across different speakers. To address this issue, we focus on learning phoneme-level alignments from paired whispers and text and employ a Text-to-Speech (TTS) system to synthesize the ground-truth. To reduce dependence on whispers, we learn phoneme alignments directly from NAMs, though the quality is constrained by the available training data. To further mitigate reliance on NAM/whisper data for ground-truth simulation, we propose incorporating the lip modality to infer speech and introduce a novel diffusion-based method that leverages recent advancements in lip-to-speech technology. Additionally, we release the MultiNAM dataset with over 7.96 hours of paired NAM, whisper, video, and text data from two speakers and benchmark all methods on this dataset.
@inproceedings{multinam_ICASSP_2025, author = {Shah, Neil and Karande, Shirish and Gandhi, Vineet}, title = {{Advancing NAM-to-Speech Conversion with Novel Methods and the MultiNAM Dataset}}, year = {2025}, booktitle = {International Conference on Acoustics, Speech, and Signal Processing (ICASSP)}, month = apr, } -
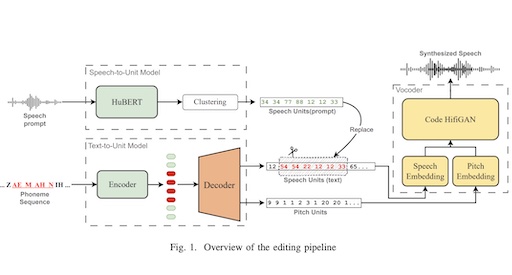 Prompt-to-Correct: Automated Test-Time Pronunciation Correction with Voice PromptsAyan Kashyap, Neil Shah, and Vineet GandhiIn International Conference on Acoustics, Speech, and Signal Processing (ICASSP), 2025
Prompt-to-Correct: Automated Test-Time Pronunciation Correction with Voice PromptsAyan Kashyap, Neil Shah, and Vineet GandhiIn International Conference on Acoustics, Speech, and Signal Processing (ICASSP), 2025Pronunciation correction is crucial for Text-to- Speech (TTS) systems in production. Traditional methods, which rely on phoneme sequence manipulation, are often cumbersome and error-prone. To address this, we propose Prompt-to-Correct, an editing-based methodology for pronunciation correction in TTS systems using voice prompts. Our approach enables ac- curate, granular corrections at test-time without the need for additional training or fine-tuning. Unlike existing speech edit- ing methods, we eliminate the need for external alignment to determine edit boundaries. By simply providing a correctly- pronounced reading of a word in any voice or accent, our system successfully corrects mispronunciations while maintaining continuity. Experimental results demonstrate that our method outperforms traditional baselines and state-of-the-art speech editing techniques.
@inproceedings{Kashyap_ICASSP_2025, author = {Kashyap, Ayan and Shah, Neil and Gandhi, Vineet}, title = {{Prompt-to-Correct: Automated Test-Time Pronunciation Correction with Voice Prompts}}, year = {2025}, booktitle = {International Conference on Acoustics, Speech, and Signal Processing (ICASSP)}, month = apr, } -
 Minimalistic Video Saliency Prediction via Efficient Decoder & Spatio Temporal Action CuesRohit Girmaji, Siddharth Jain, Bhav Beri, Sarthak Bansal, and Vineet GandhiIn International Conference on Acoustics, Speech, and Signal Processing (ICASSP), 2025
Minimalistic Video Saliency Prediction via Efficient Decoder & Spatio Temporal Action CuesRohit Girmaji, Siddharth Jain, Bhav Beri, Sarthak Bansal, and Vineet GandhiIn International Conference on Acoustics, Speech, and Signal Processing (ICASSP), 2025This paper introduces ViNet-S, a 36MB model based on the ViNet architecture with a U-Net design, featuring a lightweight decoder that significantly reduces model size and parameters without compromising performance. Additionally, ViNet-A (148MB) incorporates spatio-temporal action localization (STAL) features, differing from traditional video saliency models that use action classification backbones. Our studies show that an ensemble of ViNet-S and ViNet-A, by averaging predicted saliency maps, achieves state-of-the-art performance on three visual-only and six audio-visual saliency datasets, outperforming transformer-based models in both parameter efficiency and real-time performance, with ViNet-S reaching over 1000fps.
@inproceedings{Girmaji_ICASSP_2025, author = {Girmaji, Rohit and Jain, Siddharth and Beri, Bhav and Bansal, Sarthak and Gandhi, Vineet}, title = {{Minimalistic Video Saliency Prediction via Efficient Decoder & Spatio Temporal Action Cues}}, year = {2025}, booktitle = {International Conference on Acoustics, Speech, and Signal Processing (ICASSP)}, month = apr, } -
 EditIQ: Automated Cinematic Editing of Static Wide-Angle Videos via Dialogue Interpretation and Saliency CuesRohit Girmaji, Bhav Beri, Ramanathan Subramanian, and Vineet GandhiIn Intelligent User interfaces (IUI), 2025
EditIQ: Automated Cinematic Editing of Static Wide-Angle Videos via Dialogue Interpretation and Saliency CuesRohit Girmaji, Bhav Beri, Ramanathan Subramanian, and Vineet GandhiIn Intelligent User interfaces (IUI), 2025We present EditIQ, a completely automated framework for cinematically editing scenes captured via a stationary, large field-of-view and high-resolution camera. From the static camera feed, EditIQ initially generates multiple virtual feeds, emulating a team of cameramen. These virtual camera shots termed rushes are subsequently assembled using an automated editing algorithm, whose objective is to present the viewer with the most vivid scene content. To understand key scene elements and guide the editing process, we employ a two-pronged approach: (1) a large language model (LLM)-based dialogue understanding module to analyze conversational flow, coupled with (2) visual saliency prediction to identify meaningful scene elements and camera shots therefrom. We then formulate cinematic video editing as an energy minimization problem over shot selection, where cinematic constraints determine shot choices, transitions, and continuity. EditIQ synthesizes an aesthetically and visually compelling representation of the original narrative while maintaining cinematic coherence and a smooth viewing experience. Efficacy of EditIQ against competing baselines is demonstrated via a psychophysical study involving twenty participants on the BBC Old School dataset plus eleven theatre performance videos. Video samples from EditIQ can be found at https://editiq-ave.github.io/.
@inproceedings{Girmaji_IUI_2025, author = {Girmaji, Rohit and Beri, Bhav and Subramanian, Ramanathan and Gandhi, Vineet}, title = {{EditIQ: Automated Cinematic Editing of Static Wide-Angle Videos via Dialogue Interpretation and Saliency Cues}}, year = {2025}, booktitle = {Intelligent User interfaces (IUI)}, month = mar, }
2024
-
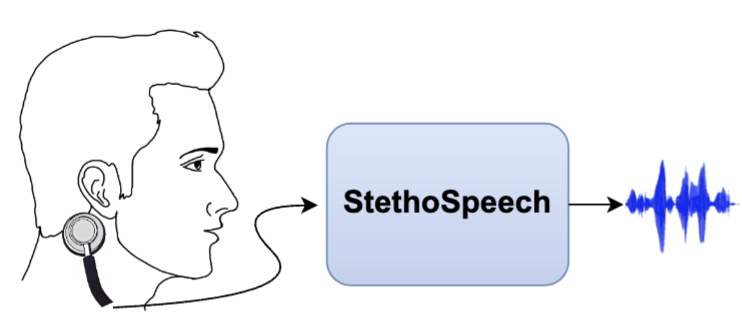 StethoSpeech: Speech Generation Through a Clinical Stethoscope Attached to the SkinNeil Shah, Neha Sahipjohn, Vishal Tambrahalli, Ramanathan Subramanian, and Vineet GandhiUBICOMP 2024, to appear in ACM Interactive, Mobile, Wearable and Ubiquitous Technologies, 2024
StethoSpeech: Speech Generation Through a Clinical Stethoscope Attached to the SkinNeil Shah, Neha Sahipjohn, Vishal Tambrahalli, Ramanathan Subramanian, and Vineet GandhiUBICOMP 2024, to appear in ACM Interactive, Mobile, Wearable and Ubiquitous Technologies, 2024We introduce StethoSpeech, a silent speech interface that transforms flesh-conducted vibrations behind the ear into speech. This innovation is designed to improve social interactions for those with voice disorders, and furthermore enable discreet public communication. Unlike prior efforts, StethoSpeech does not require (a) paired-speech data for recorded vibrations and (b) a specialized device for recording vibrations, as it can work with an off-the-shelf clinical stethoscope. The novelty of our framework lies in the overall design, simulation of the ground-truth speech, and a sequence-to-sequence translation network, which works in the latent space. We present comprehensive experiments on the existing CSTR NAM TIMIT Plus corpus and our proposed StethoText: a large-scale synchronized database of non-audible murmur and text for speech research. Our results show that StethoSpeech provides natural-sounding and intelligible speech, significantly outperforming existing methods on several quantitative and qualitative metrics. Additionally, we showcase its capacity to extend its application to speakers not encountered during training and its effectiveness in challenging, noisy environments. Speech samples are available at https://stethospeech.github.io/StethoSpeech/
@article{NEIL_ubicomb_2024, title = {StethoSpeech: Speech Generation Through a Clinical Stethoscope Attached to the Skin}, author = {Shah, Neil and Sahipjohn, Neha and Tambrahalli, Vishal and Subramanian, Ramanathan and Gandhi, Vineet}, journal = {UBICOMP 2024, to appear in ACM Interactive, Mobile, Wearable and Ubiquitous Technologies}, month = nov, year = {2024}, } -
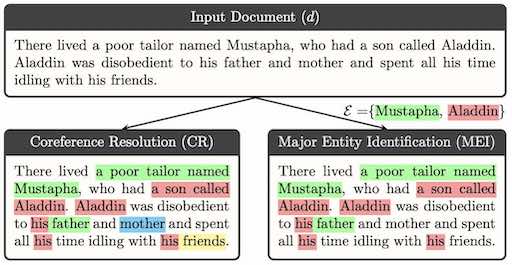 Major Entity Identification: A Generalizable Alternative to Coreference ResolutionKawshik Manikantan, Shubham Toshniwal, Tapaswi Makarand, and Vineet GandhiIn Empirical Methods in Natural Language Processing (EMNLP), 2024
Major Entity Identification: A Generalizable Alternative to Coreference ResolutionKawshik Manikantan, Shubham Toshniwal, Tapaswi Makarand, and Vineet GandhiIn Empirical Methods in Natural Language Processing (EMNLP), 2024The limited generalization of coreference resolution (CR) models has been a major bottleneck in the task’s broad application. Prior work has identified annotation differences, especially for mention detection, as one of the main reasons for the generalization gap and proposed using additional annotated target domain data. Rather than relying on this additional annotation, we propose an alternative formulation of the CR task, Major Entity Identification (MEI), where we: (a) assume the target entities to be specified in the input, and (b) limit the task to only the frequent entities. Through extensive experiments, we demonstrate that MEI models generalize well across domains on multiple datasets with supervised models and LLM-based few-shot prompting. Additionally, the MEI task fits the classification framework, which enables the use of classification-based metrics that are more robust than the current CR metrics. Finally, MEI is also of practical use as it allows a user to search for all mentions of a particular entity or a group of entities of interest
@inproceedings{bib_mei_2024, author = {Manikantan, Kawshik and Toshniwal, Shubham and Makarand, Tapaswi and Gandhi, Vineet}, title = {Major Entity Identification: A Generalizable Alternative to Coreference Resolution}, booktitle = {Empirical Methods in Natural Language Processing (EMNLP)}, year = {2024}, month = nov, } -
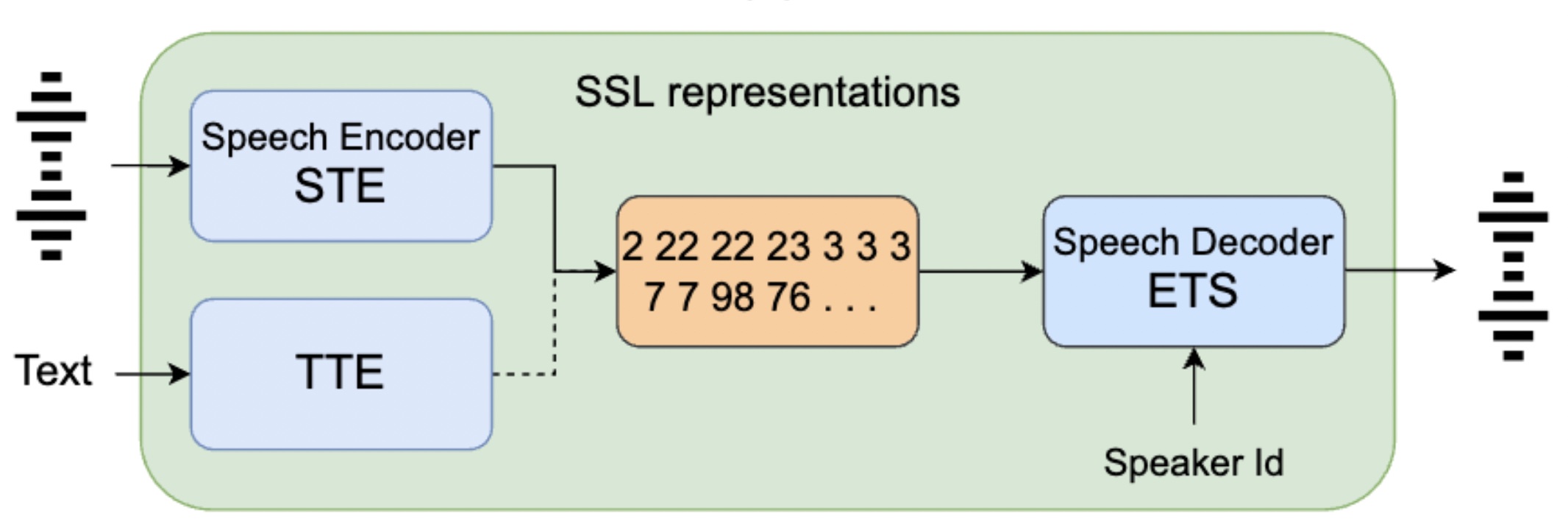 ParrotTTS: Text-to-speech synthesis exploiting disentangled self-supervised representationsNeil Shah, Saiteja Kosgi, Vishal Tambrahalli, Sahipjohn, Anil Kumar Nelakanti, and Vineet GandhiIn Findings of the Association for Computational Linguistics (EACL), 2024
ParrotTTS: Text-to-speech synthesis exploiting disentangled self-supervised representationsNeil Shah, Saiteja Kosgi, Vishal Tambrahalli, Sahipjohn, Anil Kumar Nelakanti, and Vineet GandhiIn Findings of the Association for Computational Linguistics (EACL), 2024@inproceedings{bib_parrotTTS_2024, author = {Shah, Neil and Kosgi, Saiteja and Tambrahalli, Vishal and Sahipjohn and Nelakanti, Anil Kumar and Gandhi, Vineet}, title = {ParrotTTS: Text-to-speech synthesis exploiting disentangled self-supervised representations}, booktitle = {Findings of the Association for Computational Linguistics (EACL)}, year = {2024} }
2023
-
 Test-Time Amendment with a Coarse Classifier for Fine-Grained ClassificationKanishk Jain, Shyamgopal Karthik, and Vineet GandhiIn Conference on Neural Information Processing Systems (Neurips), 2023
Test-Time Amendment with a Coarse Classifier for Fine-Grained ClassificationKanishk Jain, Shyamgopal Karthik, and Vineet GandhiIn Conference on Neural Information Processing Systems (Neurips), 2023We investigate the problem of reducing mistake severity for fine-grained classification. Fine-grained classification can be challenging, mainly due to the requirement of knowledge or domain expertise for accurate annotation. However, humans are particularly adept at performing coarse classification as it requires relatively low levels of expertise. To this end, we present a novel approach for Post-Hoc Correction called Hierarchical Ensembles (HiE) that utilizes label hierarchy to improve the performance of fine-grained classification at test-time using the coarse-grained predictions. By only requiring the parents of leaf nodes, our method significantly reduces avg. mistake severity while improving top-1 accuracy on the iNaturalist-19 and tieredImageNet-H datasets, achieving a new state-of-the-art on both benchmarks. We also investigate the efficacy of our approach in the semi-supervised setting. Our approach brings notable gains in top-1 accuracy while significantly decreasing the severity of mistakes as training data decreases for the fine-grained classes. The simplicity and post-hoc nature of HiE render it practical to be used with any off-the-shelf trained model to improve its predictions further.
@inproceedings{bib_hie_2023, author = {Jain, Kanishk and Karthik, Shyamgopal and Gandhi, Vineet}, title = {Test-Time Amendment with a Coarse Classifier for Fine-Grained Classification}, booktitle = {Conference on Neural Information Processing Systems (Neurips)}, year = {2023}, } -
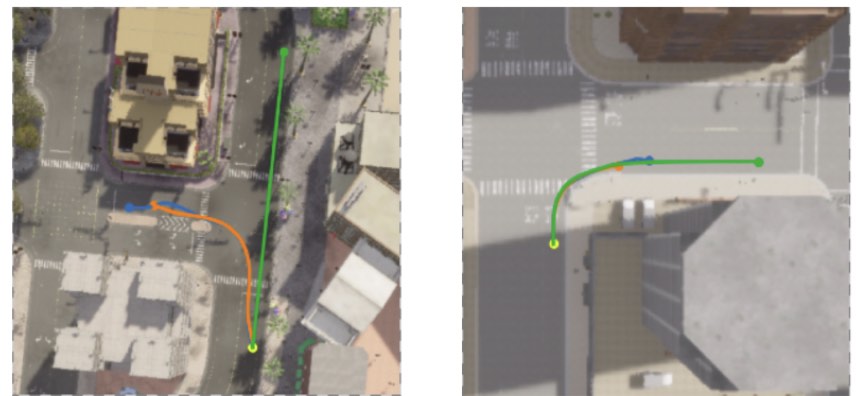 Ground then Navigate: Language-guided Navigation in Dynamic ScenesKanishk Jain, Varun Chhangani, Amogh Tiwari, Madhava Krishna, and Vineet GandhiIn International Conference on Robotics and Automation (ICRA), 2023
Ground then Navigate: Language-guided Navigation in Dynamic ScenesKanishk Jain, Varun Chhangani, Amogh Tiwari, Madhava Krishna, and Vineet GandhiIn International Conference on Robotics and Automation (ICRA), 2023We investigate the Vision-and-Language Navigation (VLN) problem in the context of autonomous driving in outdoor settings. We solve the problem by explicitly grounding the navigable regions corresponding to the textual command. At each timestamp, the model predicts a segmentation mask corresponding to the intermediate or the final navigable region. Our work contrasts with existing efforts in VLN, which pose this task as a node selection problem, given a discrete connected graph corresponding to the environment. We do not assume the availability of such a discretised map. Our work moves towards continuity in action space, provides interpretability through visual feedback and allows VLN on commands requiring finer manoeuvres like "park between the two cars". Furthermore, we propose a novel meta-dataset CARLA-NAV to allow efficient training and validation. The dataset comprises pre-recorded training sequences and a live environment for validation and testing. We provide extensive qualitative and quantitive empirical results to validate the efficacy of the proposed approach.
@inproceedings{bib_icra_2023, author = {Jain, Kanishk and Chhangani, Varun and Tiwari, Amogh and Krishna, Madhava and Gandhi, Vineet}, title = {Ground then Navigate: Language-guided Navigation in Dynamic Scenes}, booktitle = {International Conference on Robotics and Automation (ICRA)}, year = {2023}, } -
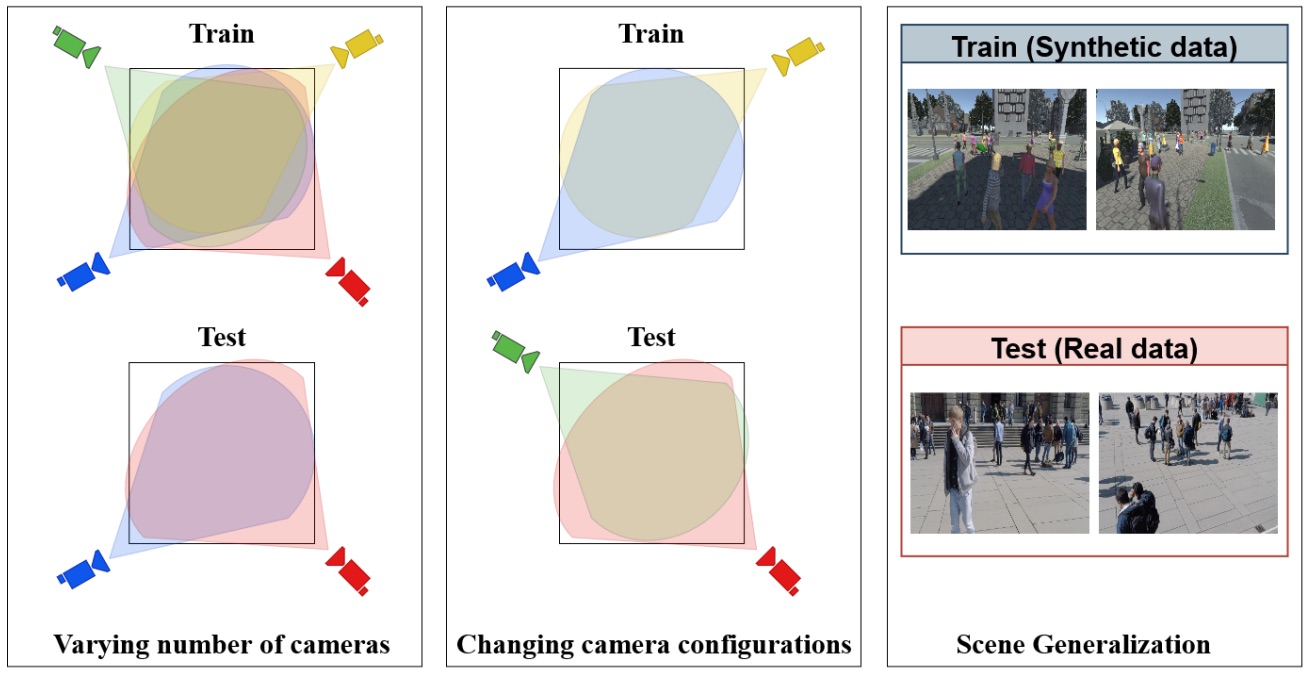 Bringing Generalization to Deep Multi-view DetectionJeet Vora, Swetanjal Dutta, Shyamgopal Karthik, and Vineet GandhiIn Winter Conference on Applications of Computer Vision Workshops (WACV-W), 2023
Bringing Generalization to Deep Multi-view DetectionJeet Vora, Swetanjal Dutta, Shyamgopal Karthik, and Vineet GandhiIn Winter Conference on Applications of Computer Vision Workshops (WACV-W), 2023@inproceedings{mvdet_jeet_2023, author = {Vora, Jeet and Dutta, Swetanjal and Karthik, Shyamgopal and Gandhi, Vineet}, title = {Bringing Generalization to Deep Multi-view Detection}, booktitle = {Winter Conference on Applications of Computer Vision Workshops (WACV-W)}, year = {2023} }
2022
-
 Does Audio help in deep Audio-Visual Saliency prediction models?Ritvik Agrawal, Shreyank Jyoti, Rohit Girmaji, Sarath Sivaprasad Sivaprasad, and Vineet GandhiIn International Conference on Multimodal Interaction (ICMI), 2022Note: Best student paper award
Does Audio help in deep Audio-Visual Saliency prediction models?Ritvik Agrawal, Shreyank Jyoti, Rohit Girmaji, Sarath Sivaprasad Sivaprasad, and Vineet GandhiIn International Conference on Multimodal Interaction (ICMI), 2022Note: Best student paper awardDespite existing works of Audio-Visual Saliency Prediction (AVSP) models claiming to achieve promising results by fusing audio modality over visual-only models, these models fail to leverage audio information. In this paper, we investigate the relevance of audio cues in conjunction with the visual ones and conduct extensive analysis by employing well-established audio modules and fusion techniques from diverse correlated audio-visual tasks. Our analysis on ten diverse saliency datasets suggests that none of the methods worked for incorporating audio. Furthermore, we bring to light, why AVSP models show a gain in performance over visual-only models, though the audio branch is agnostic at inference. Our work questions the role of audio in current deep AVSP models and motivates the community to a clear avenue for reconsideration of the complex architectures by demonstrating that simpler alternatives work equally well.
@inproceedings{Ritvik-icmi-2022, author = {Agrawal, Ritvik and Jyoti, Shreyank and Girmaji, Rohit and Sivaprasad, Sarath Sivaprasad and Gandhi, Vineet}, title = {Does Audio help in deep Audio-Visual Saliency prediction models?}, booktitle = { International Conference on Multimodal Interaction (ICMI)}, note = {Note: Best student paper award}, year = {2022} } -
 Empathic Machines: Using Intermediate Features as Levers to Emulate Emotions in Text-To-Speech SystemsIn North American Chapter of the Association for Computational Linguistics (NAACL), 2022
Empathic Machines: Using Intermediate Features as Levers to Emulate Emotions in Text-To-Speech SystemsIn North American Chapter of the Association for Computational Linguistics (NAACL), 2022We present a method to control the emotional prosody of Text to Speech (TTS) systems by using phoneme-level intermediate features (pitch, energy, and duration) as levers. As a key idea, we propose Differential Scaling (DS) to disentangle features relating to affective prosody from those arising due to acoustics conditions and speaker identity. With thorough experimental studies, we show that the proposed method improves over the prior art in accurately emulating the desired emotions while retaining the naturalness of speech. We extend the traditional evaluation of using individual sentences for a more complete evaluation of HCI systems. We present a novel experimental setup by replacing an actor with a TTS system in offline and live conversations. The emotion to be rendered is either predicted or manually assigned. The results show that the proposed method is strongly preferred over the state-of-the-art TTS system and adds the much-coveted “human touch” in machine dialogue. Audio samples for our experiments and the code are available at: https://emtts.github.io/tts-demo/
@inproceedings{Sai-naacl-2022, author = {}, title = {Empathic Machines: Using Intermediate Features as Levers to Emulate Emotions in Text-To-Speech Systems}, booktitle = {North American Chapter of the Association for Computational Linguistics (NAACL)}, year = {2022}, month = jul, } -
 Comprehensive Multi-Modal Interactions for Referring Image SegmentationKanishk Jain and Vineet GandhiIn Findings of Association for Computational Linguistics (ACL), 2022
Comprehensive Multi-Modal Interactions for Referring Image SegmentationKanishk Jain and Vineet GandhiIn Findings of Association for Computational Linguistics (ACL), 2022We investigate Referring Image Segmentation (RIS), which outputs a segmentation map corresponding to the given natural language description. To solve RIS efficiently, we need to understand each word’s relationship with other words, each region in the image to other regions, and cross-modal alignment between linguistic and visual domains. Recent methods model these three types of interactions sequentially. We argue that such a modular approach limits these methods’ performance, and joint simultaneous reasoning can help resolve ambiguities. To this end, we propose a Joint Reasoning (JRM) module and a novel Cross-Modal Multi-Level Fusion (CMMLF) module for tackling this task. JRM effectively models the referent’s multi-modal context by jointly reasoning over visual and linguistic modalities (performing word-word, image region-region, word-region interactions in a single module). CMMLF module further refines the segmentation masks by exchanging contextual information across visual hierarchy through linguistic features acting as a bridge. We present thorough ablation studies and validate our approach’s performance on four benchmark datasets, and show that the proposed method outperforms the existing state-of-the-art methods on all four datasets by significant margins.
@inproceedings{Kanishk-arxiv-2021, author = {Jain, Kanishk and Gandhi, Vineet}, title = {Comprehensive Multi-Modal Interactions for Referring Image Segmentation}, booktitle = {Findings of Association for Computational Linguistics (ACL)}, year = {2022}, month = may } -
 Reappraising Domain Generalization in Neural NetworksSarath Sivaprasad, Akshay Goindani, Vaibhav Garg, and Vineet GandhiIn arXiv:2110.07981, 2022
Reappraising Domain Generalization in Neural NetworksSarath Sivaprasad, Akshay Goindani, Vaibhav Garg, and Vineet GandhiIn arXiv:2110.07981, 2022@inproceedings{bib_dg_2022, author = {Sivaprasad, Sarath and Goindani, Akshay and Garg, Vaibhav and Gandhi, Vineet}, title = {Reappraising Domain Generalization in Neural Networks}, booktitle = {arXiv:2110.07981}, year = {2022} }
2021
-
 Grounding Linguistic Commands to Navigable RegionsNivedita Rufus, Kanishk Jain, Unni Krishnan R Nair, Vineet Gandhi, and K Madhava KrishnaIn International Conference on Intelligent Robots and Systems (IROS), 2021
Grounding Linguistic Commands to Navigable RegionsNivedita Rufus, Kanishk Jain, Unni Krishnan R Nair, Vineet Gandhi, and K Madhava KrishnaIn International Conference on Intelligent Robots and Systems (IROS), 2021Humans have a natural ability to effortlessly comprehend linguistic commands such as “park next to the yellow sedan” and instinctively know which region of the road the vehicle should navigate. Extending this ability to autonomous vehicles is the next step towards creating fully autonomous agents that respond and act according to human commands. To this end, we propose the novel task of Referring Navigable Regions (RNR), i.e., grounding regions of interest for navigation based on the linguistic command. RNR is different from Referring Image Segmentation (RIS), which focuses on grounding an object referred to by the natural language expression instead of grounding a navigable region. For example, for a command “park next to the yellow sedan,” RIS will aim to segment the referred sedan, and RNR aims to segment the suggested parking region on the road. We introduce a new dataset, Talk2Car-RegSeg, which extends the existing Talk2car [1] dataset with segmentation masks for the regions described by the linguistic commands. A separate test split with concise manoeuvre-oriented commands is provided to assess the practicality of our dataset. We benchmark the proposed dataset using a novel transformer-based architecture. We present extensive ablations and show superior performance over baselines on multiple evaluation metrics. A downstream path planner generating trajectories based on RNR outputs confirms the efficacy of the proposed framework.
@inproceedings{iros_rnr_2021, author = {Rufus, Nivedita and Jain, Kanishk and Nair, Unni Krishnan R and Gandhi, Vineet and Krishna, K Madhava}, title = {Grounding Linguistic Commands to Navigable Regions}, booktitle = {International Conference on Intelligent Robots and Systems (IROS)}, year = {2021}, } -
 ViNet: Pushing the limits of Visual Modality for Audio-Visual Saliency PredictionSamyak Jain, Pradeep Yarlagadda, Shreyank Jyoti, Shyamgopal Karthik, Ramanathan Subramanian, and Vineet GandhiIn International Conference on Intelligent Robots and Systems (IROS), 2021
ViNet: Pushing the limits of Visual Modality for Audio-Visual Saliency PredictionSamyak Jain, Pradeep Yarlagadda, Shreyank Jyoti, Shyamgopal Karthik, Ramanathan Subramanian, and Vineet GandhiIn International Conference on Intelligent Robots and Systems (IROS), 2021We propose the ViNet architecture for audio-visual saliency prediction. ViNet is a fully convolutional encoder-decoder architecture. The encoder uses visual features from a network trained for action recognition, and the decoder infers a saliency map via trilinear interpolation and 3D convolutions, combining features from multiple hierarchies. The overall architecture of ViNet is conceptually simple; it is causal and runs in real-time (60 fps). ViNet does not use audio as input and still outperforms the state-of-the-art audio-visual saliency prediction models on nine different datasets (three visual-only and six audio-visual datasets). ViNet also surpasses human performance on the CC, SIM and AUC metrics for the AVE dataset, and to our knowledge, it is the first network to do so. We also explore a variation of ViNet architecture by augmenting audio features into the decoder. To our surprise, upon sufficient training, the network becomes agnostic to the input audio and provides the same output irrespective of the input. Interestingly, we also observe similar behaviour in the previous state-of-the-art models \citetsiami2020stavis for audio-visual saliency prediction. Our findings contrast with previous works on deep learning-based audio-visual saliency prediction, suggesting a clear avenue for future explorations incorporating audio in a more effective manner. The code and pre-trained models are available at https://github.com/samyak0210/ViNet
@inproceedings{samyak-iros-2020, author = {Jain, Samyak and Yarlagadda, Pradeep and Jyoti, Shreyank and Karthik, Shyamgopal and Subramanian, Ramanathan and Gandhi, Vineet}, title = {ViNet: Pushing the limits of Visual Modality for Audio-Visual Saliency Prediction}, booktitle = {International Conference on Intelligent Robots and Systems (IROS)}, year = {2021}, } -
 Emotional Prosody Control for Speech GenerationSarath Sivaprasad, Saiteja Kosgi, and Vineet GandhiIn Interspeech, 2021
Emotional Prosody Control for Speech GenerationSarath Sivaprasad, Saiteja Kosgi, and Vineet GandhiIn Interspeech, 2021Machine-generated speech is characterized by its limited or unnatural emotional variation. Current text to speech systems generates speech with either a flat emotion, emotion selected from a predefined set, average variation learned from prosody sequences in training data or transferred from a source style. We propose a text to speech(TTS) system, where a user can choose the emotion of generated speech from a continuous and meaningful emotion space (Arousal-Valence space). The proposed TTS system can generate speech from the text in any speaker’s style, with fine control of emotion. We show that the system works on emotion unseen during training and can scale to previously unseen speakers given his/her speech sample. Our work expands the horizon of the state-of-the-art FastSpeech2 backbone to a multi-speaker setting and gives it much-coveted continuous (and interpretable) affective control, without any observable degradation in the quality of the synthesized speech.
@inproceedings{Sarath-Interspeech-2021, author = {Sivaprasad, Sarath and Kosgi, Saiteja and Gandhi, Vineet}, title = {Emotional Prosody Control for Speech Generation}, booktitle = {Interspeech}, year = {2021}, } -
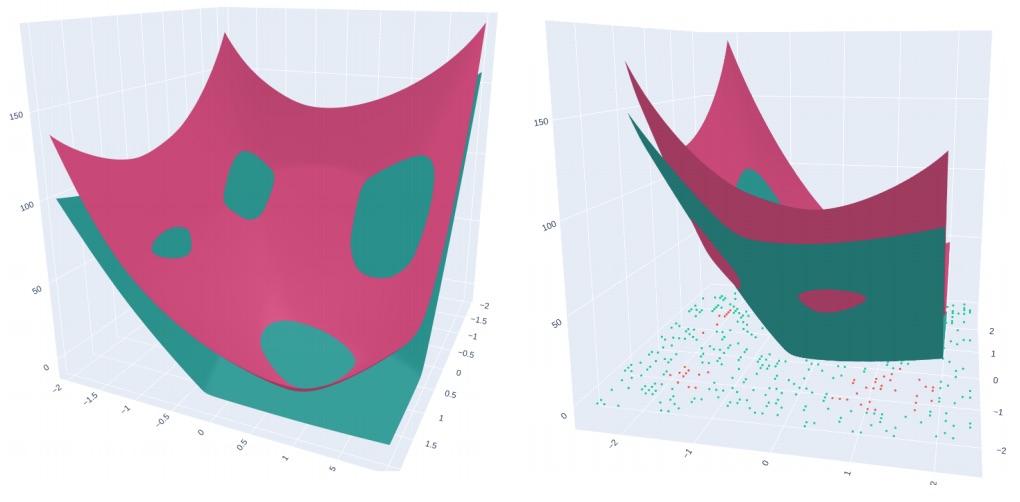 The Curious Case of Convex NetworksSarath Sivaprasad, Naresh Manwani, and Vineet GandhiIn European Conference on Machine Learning (ECML), 2021
The Curious Case of Convex NetworksSarath Sivaprasad, Naresh Manwani, and Vineet GandhiIn European Conference on Machine Learning (ECML), 2021In this paper, we investigate a constrained formulation of neural networks where the output is a convex function of the input. We show that the convexity constraints can be enforced on both fully connected and convolutional layers, making them applicable to most architectures. The convexity constraints include restricting the weights (for all but the first layer) to be non-negative and using a non-decreasing convex activation function. Albeit simple, these constraints have profound implications on the generalization abilities of the network. We draw three valuable insights: (a) Input Output Convex Networks (IOC-NN) self regularize and almost uproot the problem of overfitting; (b) Although heavily constrained, they come close to the performance of the base architectures; and (c) The ensemble of convex networks can match or outperform the non convex counterparts. We demonstrate the efficacy of the proposed idea using thorough experiments and ablation studies on MNIST, CIFAR10, and CIFAR100 datasets with three different neural network architectures. The code for this project is publicly available at: https://github.com/sarathsp1729/Convex-Networks.
@inproceedings{Sarath-IOCNN-2020, author = {Sivaprasad, Sarath and Manwani, Naresh and Gandhi, Vineet}, title = {The Curious Case of Convex Networks}, booktitle = {European Conference on Machine Learning (ECML)}, year = {2021} } -
 No Cost Likelihood Manipulation at Test Time for Making Better Mistakes in Deep NetworksShyamgopal Karthik, Ameya Prabhu, Puneet Dokania, and Vineet GandhiIn International Conference on Learning Representations (ICLR), 2021
No Cost Likelihood Manipulation at Test Time for Making Better Mistakes in Deep NetworksShyamgopal Karthik, Ameya Prabhu, Puneet Dokania, and Vineet GandhiIn International Conference on Learning Representations (ICLR), 2021There has been increasing interest in building deep hierarchy-aware classifiers, aiming to quantify and reduce the severity of mistakes and not just count the number of errors. The idea is to exploit the label hierarchy (e.g., WordNet ontology) and consider graph distances as a proxy for mistake severity. Surprisingly, on examining mistake-severity distributions of the top-1 prediction, we find that current state-of-the-art hierarchy-aware deep classifiers do not show practical improvement in making better mistakes than the standard cross-entropy baseline. In fact, they reduce the average mistake-severity metric by largely making additional low-severity or easily avoidable mistakes. This might explain the noticeable accuracy drop. To this end, we resort to the classical Conditional Risk Minimization (CRM) framework for hierarchy aware classification. Given a cost matrix and a reliable estimate of likelihoods (obtained from a trained network), CRM simply amends mistakes at inference time; it needs no extra parameters; it requires adding just one line of code to the standard cross-entropy baseline. It significantly outperforms the state-of-the-art and consistently obtains large reductions in the average hierarchical distance of top-k predictions across datasets, with very little loss in accuracy. Since CRM does not require retraining or fine-tuning of any hyperparameter, it can be used with any off-the-shelf cross-entropy trained model.
@inproceedings{Shyam-iclr-2021, author = {Karthik, Shyamgopal and Prabhu, Ameya and Dokania, Puneet and Gandhi, Vineet}, title = {No Cost Likelihood Manipulation at Test Time for Making Better Mistakes in Deep Networks}, booktitle = {International Conference on Learning Representations (ICLR)}, year = {2021}, }
2020
-
 Simple Unsupervised Multi-Object TrackingShyamgopal Karthik, Ameya Prabhu, and Vineet GandhiIn arXiv:2006.02609, 2020
Simple Unsupervised Multi-Object TrackingShyamgopal Karthik, Ameya Prabhu, and Vineet GandhiIn arXiv:2006.02609, 2020Multi-object tracking has seen a lot of progress recently, albeit with substantial annotation costs for developing better and larger labeled datasets. In this work, we remove the need for annotated datasets by proposing an unsupervised re-identification network, thus sidestepping the labeling costs entirely, required for training. Given unlabeled videos, our proposed method (SimpleReID) first generates tracking labels using SORT and trains a ReID network to predict the generated labels using crossentropy loss. We demonstrate that SimpleReID performs substantially better than simpler alternatives, and we recover the full performance of its supervised counterpart consistently across diverse tracking frameworks. The observations are unusual because unsupervised ReID is not expected to excel in crowded scenarios with occlusions, and drastic viewpoint changes. By incorporating our unsupervised SimpleReID with CenterTrack trained on augmented still images, we establish a new state-of-the-art performance on popular datasets like MOT16/17 without using tracking supervision, beating current best (CenterTrack) by 0.2-0.3 MOTA and 4.4-4.8 IDF1 scores. We further provide evidence for limited scope for improvement in IDF1 scores beyond our unsupervised ReID in the studied settings. Our investigation suggests reconsideration towards more sophisticated, supervised, end-to-end trackers by showing promise in simpler unsupervised alternatives.
@inproceedings{Shyam-Arxiv-2020, author = {Karthik, Shyamgopal and Prabhu, Ameya and Gandhi, Vineet}, title = {Simple Unsupervised Multi-Object Tracking}, booktitle = {arXiv:2006.02609}, year = {2020} } -
 LiDAR guided Small obstacle SegmentationAasheesh Singh, Aditya Kamireddypalli, Vineet Gandhi, and K Madhava KrishnaIn International Conference on Intelligent Robots and Systems (IROS), 2020
LiDAR guided Small obstacle SegmentationAasheesh Singh, Aditya Kamireddypalli, Vineet Gandhi, and K Madhava KrishnaIn International Conference on Intelligent Robots and Systems (IROS), 2020Detecting small obstacles on the road is critical for autonomous driving. In this paper, we present a method to reliably detect such obstacles through a multi-modal framework of sparse LiDAR(VLP-16) and Monocular vision. LiDAR is employed to provide additional context in the form of confidence maps to monocular segmentation networks. We show significant performance gains when the context is fed as an additional input to monocular semantic segmentation frameworks. We further present a new semantic segmentation dataset to the community, comprising of over 3000 image frames with corresponding LiDAR observations. The images come with pixel-wise annotations of three classes off-road, road, and small obstacle. We stress that precise calibration between LiDAR and camera is crucial for this task and thus propose a novel Hausdorff distance based calibration refinement method over extrinsic parameters. As a first benchmark over this dataset, we report our results with 73% instance detection up to a distance of 50 meters on challenging scenarios. Qualitatively by showcasing accurate segmentation of obstacles less than 15 cms at 50m depth and quantitatively through favourable comparisons vis a vis prior art, we vindicate the method’s efficacy. Our project-page and Dataset is hosted at https://small-obstacle-dataset.github.io/
@inproceedings{aavk-IROS-2020, author = {Singh, Aasheesh and Kamireddypalli, Aditya and Gandhi, Vineet and Krishna, K Madhava}, title = {LiDAR guided Small obstacle Segmentation}, booktitle = {International Conference on Intelligent Robots and Systems (IROS)}, year = {2020} } -
 Tidying Deep Saliency Prediction ArchitecturesNavyasri Reddy, Samyak Jain, Pradeep Yarlagadda, and Vineet GandhiIn International Conference on Intelligent Robots and Systems (IROS), 2020
Tidying Deep Saliency Prediction ArchitecturesNavyasri Reddy, Samyak Jain, Pradeep Yarlagadda, and Vineet GandhiIn International Conference on Intelligent Robots and Systems (IROS), 2020Learning computational models for visual attention (saliency estimation) is an effort to inch machines/robots closer to human visual cognitive abilities. Data-driven efforts have dominated the landscape since the introduction of deep neural network architectures. In deep learning research, the choices in architecture design are often empirical and frequently lead to more complex models than necessary. The complexity, in turn, hinders the application requirements. In this paper, we identify four key components of saliency models, i.e., input features, multi-level integration, readout architecture, and loss functions. We review the existing state of the art models on these four components and propose novel and simpler alternatives. As a result, we propose two novel end-to-end architectures called SimpleNet and MDNSal, which are neater, minimal, more interpretable and achieve state of the art performance on public saliency benchmarks. SimpleNet is an optimized encoder-decoder architecture and brings notable performance gains on the SALICON dataset (the largest saliency benchmark). MDNSal is a parametric model that directly predicts parameters of a GMM distribution and is aimed to bring more interpretability to the prediction maps. The proposed saliency models can be inferred at 25fps, making them suitable for real-time applications. Code and pre-trained models are available at https://github.com/samyak0210/saliency
@inproceedings{Navya-IROS-2020, author = {Reddy, Navyasri and Jain, Samyak and Yarlagadda, Pradeep and Gandhi, Vineet}, title = {Tidying Deep Saliency Prediction Architectures}, booktitle = {International Conference on Intelligent Robots and Systems (IROS)}, year = {2020}, } -
 GAZED - Gaze-guided Cinematic Editing of Wide-Angle Monocular Video RecordingsBhanu K L Moorthy, Moneish Kumar, Ramanathan Subramanian, and Vineet GandhiIn Conference on Human Factors in Computing Systems (CHI), 2020
GAZED - Gaze-guided Cinematic Editing of Wide-Angle Monocular Video RecordingsBhanu K L Moorthy, Moneish Kumar, Ramanathan Subramanian, and Vineet GandhiIn Conference on Human Factors in Computing Systems (CHI), 2020We present GAZED, eye GAZe-guided EDiting for videos captured by a solitary, static, wide-angle and high-resolution camera. Eye-gaze has been effectively employed in computational applications as a cue to capture interesting scene content; we employ gaze as a proxy to select shots for inclusion in the edited video. Given the original video, scene content and user eye-gaze tracks are combined to generate an edited video comprising cinematically valid actor shots and shot transitions to generate an aesthetic and vivid representation of the original narrative. We model cinematic video editing as an energy minimization problem over shot selection, whose constraints capture cinematographic editing conventions. Gazed scene locations primarily determine the shots constituting the edited video. Effectiveness of GAZED against multiple competing methods is demonstrated via a psychophysical study involving 12 users and twelve performance videos.
@inproceedings{Bhanu-CHI-2020, author = {Moorthy, Bhanu K L and Kumar, Moneish and Subramanian, Ramanathan and Gandhi, Vineet}, title = {GAZED - Gaze-guided Cinematic Editing of Wide-Angle Monocular Video Recordings}, booktitle = {Conference on Human Factors in Computing Systems (CHI)}, year = {2020}, } -
 Exploring 3 R’s of Long-term Tracking: Re-detection, Recovery and ReliabilityShyamgopal Karthik, Abhinav Moudgil, and Vineet GandhiIn Winter Conference on Applications of Computer Vision (WACV), 2020
Exploring 3 R’s of Long-term Tracking: Re-detection, Recovery and ReliabilityShyamgopal Karthik, Abhinav Moudgil, and Vineet GandhiIn Winter Conference on Applications of Computer Vision (WACV), 2020Recent works have proposed several long term tracking benchmarks and highlight the importance of moving towards long-duration tracking to bridge the gap with application requirements. The current evaluation methodologies, however, do not focus on several aspects that are crucial in a long term perspective like Re-detection, Recovery, and Reliability. In this paper, we propose novel evaluation strategies for a more in-depth analysis of trackers from a long-term perspective. More specifically, (a) we test re-detection capability of the trackers in the wild by simulating virtual cuts, (b) we investigate the role of chance in the recovery of tracker after failure and (c) we propose a novel metric allowing visual inference on the ability of a tracker to track contiguously (without any failure) at a given accuracy. We present several original insights derived from an extensive set of quantitative and qualitative experiments.
@inproceedings{Sudheer-cine-2019, author = {Karthik, Shyamgopal and Moudgil, Abhinav and Gandhi, Vineet}, title = {Exploring 3 R's of Long-term Tracking: Re-detection, Recovery and Reliability}, booktitle = {Winter Conference on Applications of Computer Vision (WACV)}, year = {2020} }
2019
-
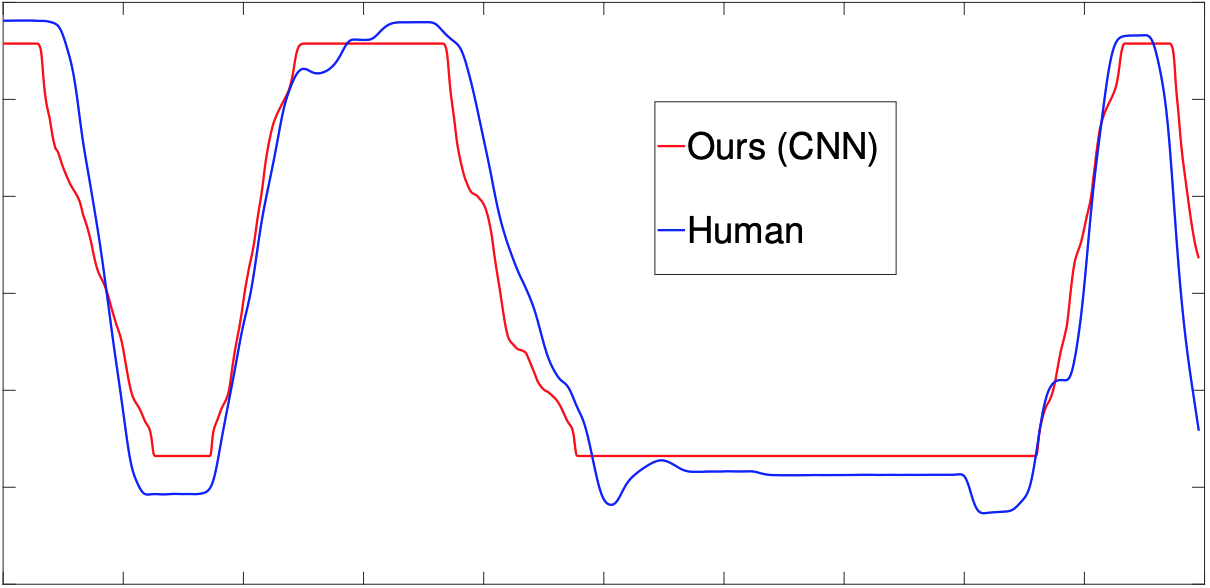 CineFilter: Unsupervised Filtering for Real Time Autonomous Camera SystemsSudheer Achary, Javed Syed Ashar, Nikita Shravan, Moorthy K L Bhanu, Vineet Gandhi, and Anoop NamboodiriIn Workshop on Intelligent Cinematography and Editing (WICED), Eurographics 2020, 2019
CineFilter: Unsupervised Filtering for Real Time Autonomous Camera SystemsSudheer Achary, Javed Syed Ashar, Nikita Shravan, Moorthy K L Bhanu, Vineet Gandhi, and Anoop NamboodiriIn Workshop on Intelligent Cinematography and Editing (WICED), Eurographics 2020, 2019Learning to mimic the smooth and deliberate camera movement of a human cameraman is an essential requirement for autonomous camera systems. This paper presents a novel formulation for online and real-time estimation of smooth camera trajectories. Many works have focused on global optimization of the trajectory to produce an offline output. Some recent works have tried to extend this to the online setting, but lack either in the quality of the camera trajectories or need large labeled datasets to train their supervised model. We propose two models, one a convex optimization based approach and another a CNN based model, both of which can exploit the temporal trends in the camera behavior. Our model is built in an unsupervised way without any ground truth trajectories and is robust to noisy outliers. We evaluate our models on two different settings namely a basketball dataset and a stage performance dataset and compare against multiple baselines and past approaches. Our models outperform other methods on quantitative and qualitative metrics and produce smooth camera trajectories that are motivated by cinematographic principles. These models can also be easily adopted to run in real-time with a low computational cost, making them fit for a variety of applications.
@inproceedings{Sudheer-cine-2020, author = {Achary, Sudheer and Ashar, Javed Syed and Shravan, Nikita and Bhanu, Moorthy K L and Gandhi, Vineet and Namboodiri, Anoop}, title = {CineFilter: Unsupervised Filtering for Real Time Autonomous Camera Systems}, booktitle = {Workshop on Intelligent Cinematography and Editing (WICED), Eurographics 2020}, year = {2019} } -
 Talk to the Vehicle: Language Conditioned Autonomous Navigation of Self Driving CarsSriram N. N., Tirth Maniar, Jayaganesh Kalyanasundaram, Vineet Gandhi, Brojeshwar Bhowmick, and Madhava K. KrishnaIn International Conference on Intelligent Robots and Systems (IROS), 2019
Talk to the Vehicle: Language Conditioned Autonomous Navigation of Self Driving CarsSriram N. N., Tirth Maniar, Jayaganesh Kalyanasundaram, Vineet Gandhi, Brojeshwar Bhowmick, and Madhava K. KrishnaIn International Conference on Intelligent Robots and Systems (IROS), 2019We propose a novel pipeline that blends encodings from natural language and 3D semantic maps obtained from computer vision data to generate local trajectories that are executed by a low-level controller. The pipeline precludes the need for a prior registered map through a local waypoint generator neural network. The waypoint generator network (WGN) maps semantics and natural language encodings (NLE) to local waypoints. A local planner then generates a trajectory from the ego location of the vehicle (an outdoor car in this case) to these locally generated waypoints while a low-level controller executes these plans faithfully. The efficacy of the pipeline is verified in the CARLA simulator environment as well as on local semantic maps built from real-world KITTI dataset. In both these environments (simulated and real-world) we show the ability of the WGN to generate waypoints accurately by mapping NLE of varying sequence lengths and levels of complexity. We compare with baseline approaches and show significant performance gain over them. And finally, we show real implementations on our electric car verifying that the pipeline lends itself to practical and tangible realizations in uncontrolled outdoor settings. In loop execution of the proposed pipeline that involves repetitive invocations of the network is critical for any such language-based navigation framework. This effort successfully accomplishes this thereby bypassing the need for prior metric maps or strategies for metric level localization during traversal.
@inproceedings{Sriram-IROS-2019, author = {N. N., Sriram and Maniar, Tirth and Kalyanasundaram, Jayaganesh and Gandhi, Vineet and Bhowmick, Brojeshwar and Krishna, Madhava K.}, title = {Talk to the Vehicle: Language Conditioned Autonomous Navigation of Self Driving Cars}, booktitle = {International Conference on Intelligent Robots and Systems (IROS)}, year = {2019}, } -
 Learning Unsupervised Visual Grounding Through Semantic Self-SupervisionSyed Ashar Javed, Saxena Shreyas, and Vineet GandhiIn International Joint Conference on Artificial Intelligence (IJCAI), 2019
Learning Unsupervised Visual Grounding Through Semantic Self-SupervisionSyed Ashar Javed, Saxena Shreyas, and Vineet GandhiIn International Joint Conference on Artificial Intelligence (IJCAI), 2019Localizing natural language phrases in images is a challenging problem that requires joint understanding of both the textual and visual modalities. In the unsupervised setting, lack of supervisory signals exacerbate this difficulty. In this paper, we propose a novel framework for unsupervised visual grounding which uses concept learning as a proxy task to obtain self-supervision. The simple intuition behind this idea is to encourage the model to localize to regions which can explain some semantic property in the data, in our case, the property being the presence of a concept in a set of images. We present thorough quantitative and qualitative experiments to demonstrate the efficacy of our approach and show a 5.6% improvement over the current state of the art on Visual Genome dataset, a 5.8% improvement on the ReferItGame dataset and comparable to state-of-art performance on the Flickr30k dataset.
@inproceedings{Javed-IJCAI-2018, author = {Javed, Syed Ashar and Shreyas, Saxena and Gandhi, Vineet}, title = {Learning Unsupervised Visual Grounding Through Semantic Self-Supervision}, booktitle = {International Joint Conference on Artificial Intelligence (IJCAI)}, year = {2019}, }
2018
-
 Nose, Eyes and Ears: Head Pose Estimation By Locating Facial KeypointsAryaman Gupta, Kalpit Thakkar, Vineet Gandhi, and P J NarayananIn International Conference on Acoustics, Speech, and Signal Processing (ICASSP), 2018
Nose, Eyes and Ears: Head Pose Estimation By Locating Facial KeypointsAryaman Gupta, Kalpit Thakkar, Vineet Gandhi, and P J NarayananIn International Conference on Acoustics, Speech, and Signal Processing (ICASSP), 2018Monocular head pose estimation requires learning a model that computes the intrinsic Euler angles for pose (yaw, pitch, roll) from an input image of human face. Annotating ground truth head pose angles for images in the wild is difficult and requires ad-hoc fitting procedures (which provides only coarse and approximate annotations). This highlights the need for approaches which can train on data captured in controlled environment and generalize on the images in the wild (with varying appearance and illumination of the face). Most present day deep learning approaches which learn a regression function directly on the input images fail to do so. To this end, we propose to use a higher level representation to regress the head pose while using deep learning architectures. More specifically, we use the uncertainty maps in the form of 2D soft localization heatmap images over five facial keypoints, namely left ear, right ear, left eye, right eye and nose, and pass them through an convolutional neural network to regress the head-pose. We show head pose estimation results on two challenging benchmarks BIWI and AFLW and our approach surpasses the state of the art on both the datasets.
@inproceedings{Gupta-arxiv-2018, author = {Gupta, Aryaman and Thakkar, Kalpit and Gandhi, Vineet and Narayanan, P J}, title = {Nose, Eyes and Ears: Head Pose Estimation By Locating Facial Keypoints}, booktitle = {International Conference on Acoustics, Speech, and Signal Processing (ICASSP)}, year = {2018} } -
 Long-Term Visual Object Tracking BenchmarkMoudgil Abhinav and Gandhi VineetIn Asian Conference on Computer Vision (ACCV), 2018
Long-Term Visual Object Tracking BenchmarkMoudgil Abhinav and Gandhi VineetIn Asian Conference on Computer Vision (ACCV), 2018In this paper, we propose a new long video dataset (called Track Long and Prosper - TLP) and benchmark for visual object tracking. The dataset consists of 50 videos from real world scenarios, encompassing a duration of over 400 minutes (676K frames), making it more than 20 folds larger in average duration per sequence and more than 8 folds larger in terms of total covered duration, as compared to existing generic datasets for visual tracking. The proposed dataset paves a way to suitably assess long term tracking performance and possibly train better deep learning architectures (avoiding/reducing augmentation, which may not reflect realistic real world behavior). We benchmark the dataset on 17 state of the art trackers and rank them according to tracking accuracy and run time speeds. We further categorize the test sequences with different attributes and present a thorough quantitative and qualitative evaluation. Our most interesting observations are (a) existing short sequence benchmarks fail to bring out the inherent differences in tracking algorithms which widen up while tracking on long sequences and (b) the accuracy of most trackers abruptly drops on challenging long sequences, suggesting the potential need of research efforts in the direction of long term tracking.
@inproceedings{moudgil-accv-2017, title = {{Long-Term Visual Object Tracking Benchmark}}, author = {Abhinav, Moudgil and Vineet, Gandhi}, booktitle = {Asian Conference on Computer Vision (ACCV)}, year = {2018}, } -
 MergeNet: A Deep Net Architecture for Small Obstacle DiscoveryKrishnam Gupta, Syed Ashar Javed, Vineet Gandhi, and Madhava K. KrishnaIn International Conference on Robotics and Automation (ICRA), 2018
MergeNet: A Deep Net Architecture for Small Obstacle DiscoveryKrishnam Gupta, Syed Ashar Javed, Vineet Gandhi, and Madhava K. KrishnaIn International Conference on Robotics and Automation (ICRA), 2018We present here, a novel network architecture called MergeNet for discovering small obstacles for on-road scenes in the context of autonomous driving. The basis of the architecture rests on the central consideration of training with less amount of data since the physical setup and the annotation process for small obstacles is hard to scale. For making effective use of the limited data, we propose a multi-stage training procedure involving weight-sharing, separate learning of low and high level features from the RGBD input and a refining stage which learns to fuse the obtained complementary features. The model is trained and evaluated on the Lost and Found dataset and is able to achieve state-of-art results with just 135 images in comparison to the 1000 images used by the previous benchmark. Additionally, we also compare our results with recent methods trained on 6000 images and show that our method achieves comparable performance with only 1000 training samples.
@inproceedings{Gupta-icra-2018, author = {Gupta, Krishnam and Javed, Syed Ashar and Gandhi, Vineet and Krishna, Madhava K.}, title = {{MergeNet: A Deep Net Architecture for Small Obstacle Discovery}}, booktitle = {International Conference on Robotics and Automation (ICRA)}, year = {2018} } -
 Watch to Edit: Video Retargeting using GazeKranthi Kumar, Moneish Kumar, Vineet Gandhi, and Ramanathan SubramanianIn Computer Graphics Forum (Eurographics edition), 2018
Watch to Edit: Video Retargeting using GazeKranthi Kumar, Moneish Kumar, Vineet Gandhi, and Ramanathan SubramanianIn Computer Graphics Forum (Eurographics edition), 2018We present a novel approach to optimally retarget videos for varied displays with differing aspect ratios by preserving salient scene content discovered via eye tracking. Our algorithm performs editing with cut, pan and zoom operations by optimizing the path of a cropping window within the original video while seeking to (i) preserve salient regions, and (ii) adhere to the principles of cinematography. Our approach is (a) content agnostic as the same methodology is employed to re-edit a wide-angle video recording or a close-up movie sequence captured with a static or moving camera, and (b) independent of video length and can in principle re-edit an entire movie in one shot. Our algorithm consists of two steps. The first step employs gaze transition cues to detect time stamps where new cuts are to be introduced in the original video via dynamic programming. A subsequent step optimizes the cropping window path (to create pan and zoom effects), while accounting for the original and new cuts. The cropping window path is designed to include maximum gaze information, and is composed of piecewise constant, linear and parabolic segments. It is obtained via L(1) regularized convex optimization which ensures a smooth viewing experience. We test our approach on a wide variety of videos and demonstrate significant improvement over the state-of-the-art, both in terms of computational complexity and qualitative aspects. A study performed with 16 users confirms that our approach results in a superior viewing experience as compared to gaze driven re-editing [JSSH15] and letterboxing methods, especially for wide-angle static camera recordings.
@inproceedings{kumar-eg-2018, title = {{Watch to Edit: Video Retargeting using Gaze}}, author = {Kumar, Kranthi and Kumar, Moneish and Gandhi, Vineet and Subramanian, Ramanathan}, booktitle = {Computer Graphics Forum (Eurographics edition)}, year = {2018}, } -
 Document Quality Estimation using Spatial Frequency ResponsePranjal Kumar Rai, Sajal Maheshwari, and Vineet GandhiIn International Conference on Acoustics, Speech, and Signal Processing (ICASSP), 2018
Document Quality Estimation using Spatial Frequency ResponsePranjal Kumar Rai, Sajal Maheshwari, and Vineet GandhiIn International Conference on Acoustics, Speech, and Signal Processing (ICASSP), 2018The current Document Image Quality Assessment (DIQA) algorithms directly relate the Optical Character Recognition (OCR) accuracies with the quality of the document to build supervised learning frameworks. This direct correlation has two major limitations: (a) OCR may be affected by factors independent of the quality of the capture and (b) it cannot account for blur variations within an image. An alternate possibility is to quantify the quality of capture using human judgement, however, it is subjective and prone to error. In this work, we build upon the idea of Spatial Frequency Re- sponse (SFR) to reliably quantify the quality of a document image. We present through quantitative and qualitative exper- iments that the proposed metric leads to significant improve- ment in document quality prediction in contrast to using OCR as ground truth.
@inproceedings{Rai-ICASSP-2018, title = {Document Quality Estimation using Spatial Frequency Response}, author = {Rai, Pranjal Kumar and Maheshwari, Sajal and Gandhi, Vineet}, booktitle = {International Conference on Acoustics, Speech, and Signal Processing (ICASSP)}, year = {2018}, } -
 An Iterative approach for Shadow Removal in Document ImagesVatsal Shah and Vineet GandhiIn International Conference on Acoustics, Speech, and Signal Processing (ICASSP), 2018
An Iterative approach for Shadow Removal in Document ImagesVatsal Shah and Vineet GandhiIn International Conference on Acoustics, Speech, and Signal Processing (ICASSP), 2018Uneven illumination and shadows in document images cause a challenge for digitization applications and automated work- flows. In this work, we propose a new method to recover un- shadowed document images from images with shadows/un- even illumination. We pose this problem as one of estimating the shading and reflectance components of the given original image. Our method first estimates the shading and uses it to compute the reflectance. The output reflectance map is then used to improve the shading and the process is repeated in an iterative manner. The iterative procedure allows for a gradual compensation and allows our algorithm to even handle diffi- cult hard shadows without introducing any artifacts. Experi- ments over two different datasets demonstrate the efficacy of our algorithm and the low computation complexity makes it suitable for most practical applications.
@inproceedings{Shah-ICASSP-2018, title = {An Iterative approach for Shadow Removal in Document Images}, author = {Shah, Vatsal and Gandhi, Vineet}, booktitle = {International Conference on Acoustics, Speech, and Signal Processing (ICASSP)}, year = {2018}, } -
 Automated Top View Registration of Broadcast Football VideosRahul Sharma, Bharath Bhat, Vineet Gandhi, and CV JawaharIn Winter Conference in Computer Vision (WACV), 2018
Automated Top View Registration of Broadcast Football VideosRahul Sharma, Bharath Bhat, Vineet Gandhi, and CV JawaharIn Winter Conference in Computer Vision (WACV), 2018In this paper, we propose a fully automatic method to register football broadcast video frames on the static top view model of the playing surface. Automatic registration has been difficult due to the difficulty of finding sufficient point correspondences. We investigate an alternate ap- proach exploiting the edge information from the line mark- ings on the field. We formulate the registration problem as a nearest neighbour search over a synthetically generated dictionary of edge map and homography pairs. The syn- thetic dictionary generation allows us to exhaustively cover a wide variety of camera angles and positions and reduces this problem to a minimal per-frame edge map matching problem. We show that the per-frame results can be fur- ther improved in videos using an optimization framework for temporal camera stabilization. We demonstrate the ef- ficacy of our approach by presenting extensive results on a dataset collected from matches of the football World Cup 2014 and show significant improvement over the current state of the art.
@inproceedings{anand-WACV-2018, title = {Automated Top View Registration of Broadcast Football Videos}, author = {Sharma, Rahul and Bhat, Bharath and Gandhi, Vineet and Jawahar, CV}, booktitle = {Winter Conference in Computer Vision (WACV)}, year = {2018}, } -
 Beyond OCRs for Document Blur EstimationPranjal Kumar Rai, Sajal Maheshwari, Ishit Mehta, Parikshit Sakurikar, and Vineet GandhiIn International Conference on Document Analysis and Recognition (ICDAR), 2018
Beyond OCRs for Document Blur EstimationPranjal Kumar Rai, Sajal Maheshwari, Ishit Mehta, Parikshit Sakurikar, and Vineet GandhiIn International Conference on Document Analysis and Recognition (ICDAR), 2018The current document blur/quality estimation algorithms rely on the OCR accuracy to measure their success. A sharp document image, however, at times may yield lower OCR accuracy owing to factors independent of blur or quality of capture. The necessity to rely on OCR is mainly due to the difficulty in quantifying the quality otherwise. In this work, we overcome this limitation by proposing a novel dataset for document blur estimation, for which we physically quantify the blur using a capture set-up which computationally varies the focal distance of the camera. We also present a selective search mechanism to improve upon the recently successful patch-based learning approaches (using codebooks or convolutional neural networks). We present a thorough analysis of the improved blur estimation pipeline using correlation with OCR accuracy as well as the actual amount of blur. Our experiments demonstrate that our method outperforms the current state-of-the-art by a significant margin.
@inproceedings{rai-icdar-2018, title = {Beyond OCRs for Document Blur Estimation}, author = {Rai, Pranjal Kumar and Maheshwari, Sajal and Mehta, Ishit and Sakurikar, Parikshit and Gandhi, Vineet}, booktitle = {International Conference on Document Analysis and Recognition (ICDAR)}, year = {2018}, }
2017
-
 Zooming On All Actors: Automatic Focus+Context Split Screen Video GenerationMoneish Kumar, Vineet Gandhi, Remi Ronfard, and Michael GleicherIn Eurographics (Computer Graphics Forum), 2017
Zooming On All Actors: Automatic Focus+Context Split Screen Video GenerationMoneish Kumar, Vineet Gandhi, Remi Ronfard, and Michael GleicherIn Eurographics (Computer Graphics Forum), 2017Recordings of stage performances are easy to capture with a high-resolution camera, but are difficult to watch because the actors’ faces are too small. We present an approach to automatically create a split screen video that transforms these recordings to show both the context of the scene as well as close-up details of the actors. Given a static recording of a stage performance and tracking information about the actors positions, our system generates videos showing a focus+context view based on computed close-up camera motions using crop-and zoom. The key to our approach is to compute these camera motions such that they are cinematically valid close-ups and to ensure that the set of views of the different actors are properly coordinated and presented. We pose the computation of camera motions as convex optimization that creates detailed views and smooth movements, subject to cinematic constraints such as not cutting faces with the edge of the frame. Additional constraints link the close up views of each actor, causing them to merge seamlessly when actors are close. Generated views are placed in a resulting layout that preserves the spatial relationships between actors. We demonstrate our results on a variety of staged theater and dance performances.
@inproceedings{moneish-eg-2017, title = {Zooming On All Actors: Automatic Focus+Context Split Screen Video Generation}, author = {Kumar, Moneish and Gandhi, Vineet and Ronfard, Remi and Gleicher, Michael}, booktitle = {Eurographics (Computer Graphics Forum)}, year = {2017}, }
2016
-
 Document Blur Detection using Edge Profile MiningPranjal Kumar Rai, Sajal Maheshwari, Gopal Sharma, and Vineet GandhiIn ICVGIP, 2016
Document Blur Detection using Edge Profile MiningPranjal Kumar Rai, Sajal Maheshwari, Gopal Sharma, and Vineet GandhiIn ICVGIP, 2016We present an algorithm for automatic blur detection of document images using a novel approach based on edge intensity profiles. Our main insight is that the edge profiles are a strong indicator of the blur present in the image, with steep profiles implying sharper regions and gradual profiles implying blurred regions. Our approach first retrieves the profiles for each point of intensity transition (each edge point) along the gradient and then uses them to output a quantitative measure indicating the extent of blur in the input image. The real time performance of the proposed approach makes it suitable for most applications. Additionally, our method works for both hand written and digital documents and is agnostic to the font types and sizes, which gives it a major advantage over the currently prevalent learning based approaches. Extensive quantitative and qualitative experiments over two different datasets show that our method outperforms almost all algorithms in current state of the art by a significant margin, especially in cross dataset experiments.
@inproceedings{rai-icvgip-2016, title = {Document Blur Detection using Edge Profile Mining}, author = {Rai, Pranjal Kumar and Maheshwari, Sajal and Sharma, Gopal and Gandhi, Vineet}, booktitle = {ICVGIP}, year = {2016}, } -
 A Computational Framework for Vertical Video EditingVineet Gandhi and Remi RonfardIn Eurographics workshop on intelligent cinematography and editing (WICED) , 2016
A Computational Framework for Vertical Video EditingVineet Gandhi and Remi RonfardIn Eurographics workshop on intelligent cinematography and editing (WICED) , 2016Vertical video editing is the process of digitally editing the image within the frame as opposed to horizontal video editing, which arranges the shots along a timeline. Vertical editing can be a time-consuming and error-prone process when using manual key-framing and simple interpolation. In this paper, we present a general framework for automatically computing a variety of cinematically plausible shots from a single input video suitable to the special case of live performances. Drawing on working practices in traditional cinematography, the system acts as a virtual camera assistant to the film editor, who can call novel shots in the edit room with a combination of high-level instructions and manually selected keyframes.
@inproceedings{gandhi-wiced-2016, title = {A Computational Framework for Vertical Video Editing}, author = {Gandhi, Vineet and Ronfard, Remi}, booktitle = {Eurographics workshop on intelligent cinematography and editing (WICED) }, year = {2016}, }
2014
-
 Multi-Clip Video Editing from a Single ViewpointVineet Gandhi, Remi Ronfard, and Michael GleicherIn European Conference on Visual Media Production (CVMP), 2014
Multi-Clip Video Editing from a Single ViewpointVineet Gandhi, Remi Ronfard, and Michael GleicherIn European Conference on Visual Media Production (CVMP), 2014We propose a framework for automatically generating multiple clips suitable for video editing by simulating pan-tilt-zoom camera movements within the frame of a single static camera. Assuming important actors and objects can be localized using computer vision techniques, our method requires only minimal user input to define the subject matter of each sub-clip. The composition of each sub-clip is automatically computed in a novel L1-norm optimization framework. Our approach encodes several common cinematographic practices into a single convex cost function minimization problem, resulting in aesthetically-pleasing sub-clips which can easily be edited together using off-the-shelf multi-clip video editing software. We demonstrate our approach on five video sequences of a live theatre performance by generating multiple synchronized sub-clips for each sequence.
@inproceedings{gandhi-cvmp-2014, title = {Multi-Clip Video Editing from a Single Viewpoint}, author = {Gandhi, Vineet and Ronfard, Remi and Gleicher, Michael}, booktitle = {European Conference on Visual Media Production (CVMP)}, year = {2014}, }
2013
-
 Detecting and naming actors in movies using generative appearance modelsVineet Gandhi and Remi RonfardIn Computer Vision and Pattern Recognition (CVPR) , 2013
Detecting and naming actors in movies using generative appearance modelsVineet Gandhi and Remi RonfardIn Computer Vision and Pattern Recognition (CVPR) , 2013We introduce a generative model for learning person and costume specific detectors from labeled examples. We demonstrate the model on the task of localizing and nam- ing actors in long video sequences. More specifically, the actor’s head and shoulders are each represented as a con- stellation of optional color regions. Detection can proceed despite changes in view-point and partial occlusions. We explain how to learn the models from a small number of la- beled keyframes or video tracks, and how to detect novel appearances of the actors in a maximum likelihood frame- work. We present results on a challenging movie example, with 81% recall in actor detection (coverage) and 89% pre- cision in actor identification (naming).
@inproceedings{gandhi-cvpr-2012, title = {Detecting and naming actors in movies using generative appearance models}, author = {Gandhi, Vineet and Ronfard, Remi}, booktitle = {Computer Vision and Pattern Recognition (CVPR) }, year = {2013}, } -
 The Prose Storyboard Language: A Tool for Annotating and Directing MoviesRemi Ronfard, Vineet Gandhi, and Laurent BoironIn Workshop on Intelligent Cinematography and Editing part of Foundations of Digital Games (FDG), 2013
The Prose Storyboard Language: A Tool for Annotating and Directing MoviesRemi Ronfard, Vineet Gandhi, and Laurent BoironIn Workshop on Intelligent Cinematography and Editing part of Foundations of Digital Games (FDG), 2013The prose storyboard language is a formal language for describing movies shot by shot, where each shot is described with a unique sentence. The language uses a simple syntax and limited vocabulary borrowed from working practices in traditional movie-making, and is intended to be readable both by machines and humans. The language is designed to serve as a high-level user interface for intelligent cinematography and editing systems.
@inproceedings{ronfard-wiced-2013, title = {The Prose Storyboard Language: A Tool for Annotating and Directing Movies}, author = {Ronfard, Remi and Gandhi, Vineet and Boiron, Laurent}, booktitle = {Workshop on Intelligent Cinematography and Editing part of Foundations of Digital Games (FDG)}, year = {2013}, }
2012
-
 High-Resolution Depth Maps Based on TOF-Stereo FusionVineet Gandhi, Jan Cech, and Radu HoraudIn International Conference on Robotics and Automation (ICRA), 2012
High-Resolution Depth Maps Based on TOF-Stereo FusionVineet Gandhi, Jan Cech, and Radu HoraudIn International Conference on Robotics and Automation (ICRA), 2012The combination of range sensors with color cameras can be very useful for robot navigation, semantic perception, manipulation, and telepresence. Several methods of combining range- and color-data have been investigated and successfully used in various robotic applications. Most of these systems suffer from the problems of noise in the range-data and resolution mismatch between the range sensor and the color cameras, since the resolution of current range sensors is much less than the resolution of color cameras. High-resolution depth maps can be obtained using stereo matching, but this often fails to construct accurate depth maps of weakly/repetitively textured scenes, or if the scene exhibits complex self-occlusions. Range sensors provide coarse depth information regardless of presence/absence of texture. The use of a calibrated system, composed of a time-of-flight (TOF) camera and of a stereoscopic camera pair, allows data fusion thus overcoming the weaknesses of both individual sensors. We propose a novel TOF-stereo fusion method based on an efficient seed-growing algorithm which uses the TOF data projected onto the stereo image pair as an initial set of correspondences. These initial ”seeds” are then propagated based on a Bayesian model which combines an image similarity score with rough depth priors computed from the low-resolution range data. The overall result is a dense and accurate depth map at the resolution of the color cameras at hand. We show that the proposed algorithm outperforms 2D image-based stereo algorithms and that the results are of higher resolution than off-the-shelf color-range sensors, e.g., Kinect. Moreover, the algorithm potentially exhibits real-time performance on a single CPU.
@inproceedings{gandhi-icra-2012, title = {High-Resolution Depth Maps Based on TOF-Stereo Fusion}, author = {Gandhi, Vineet and Cech, Jan and Horaud, Radu}, booktitle = {International Conference on Robotics and Automation (ICRA)}, year = {2012}, }